
Punstoppable
A list of puns related to "Matrix multiplication"
I've spent the past few months optimizing my matrix multiplication CUDA kernel, and finally got near cuBLAS performance on Tesla T4. In the past few weeks I've been trying to fuse all kinds of operations into the matmul kernel, such as reductions, topk search, masked_fill, and the results are looking pretty good. All of the fused kernels are much faster than the seperated versions while using much less memory.
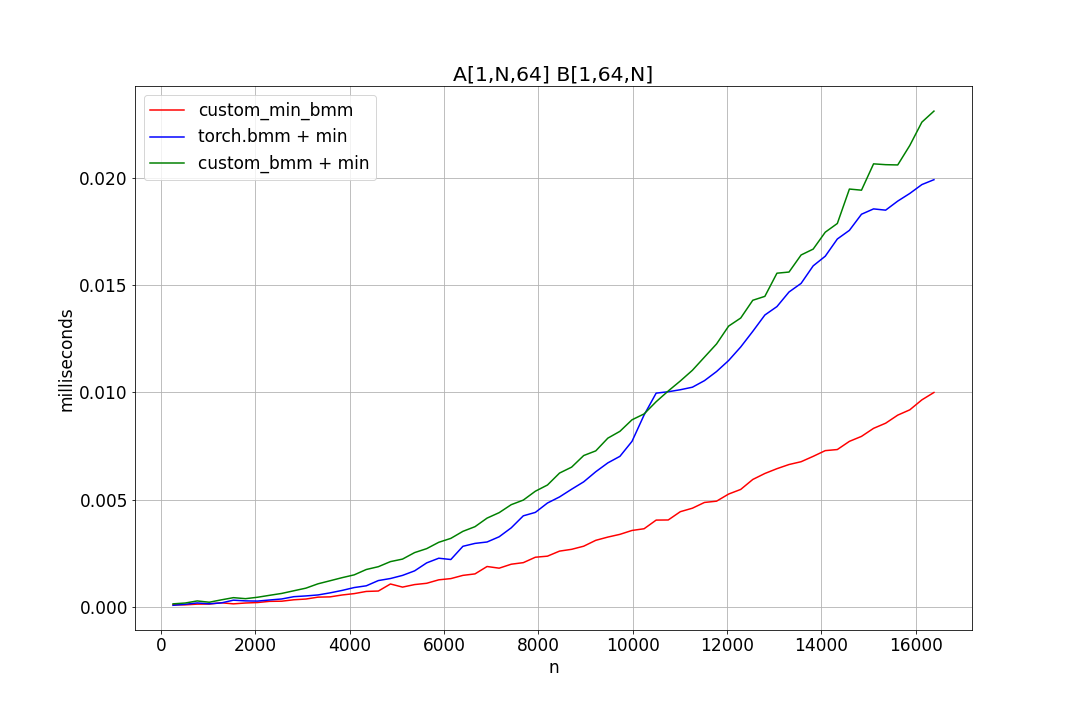
Runtime of fused MinBMM vs. torch.bmm + torch.min
edit: unit of time in this plot should be seconds, not milliseconds
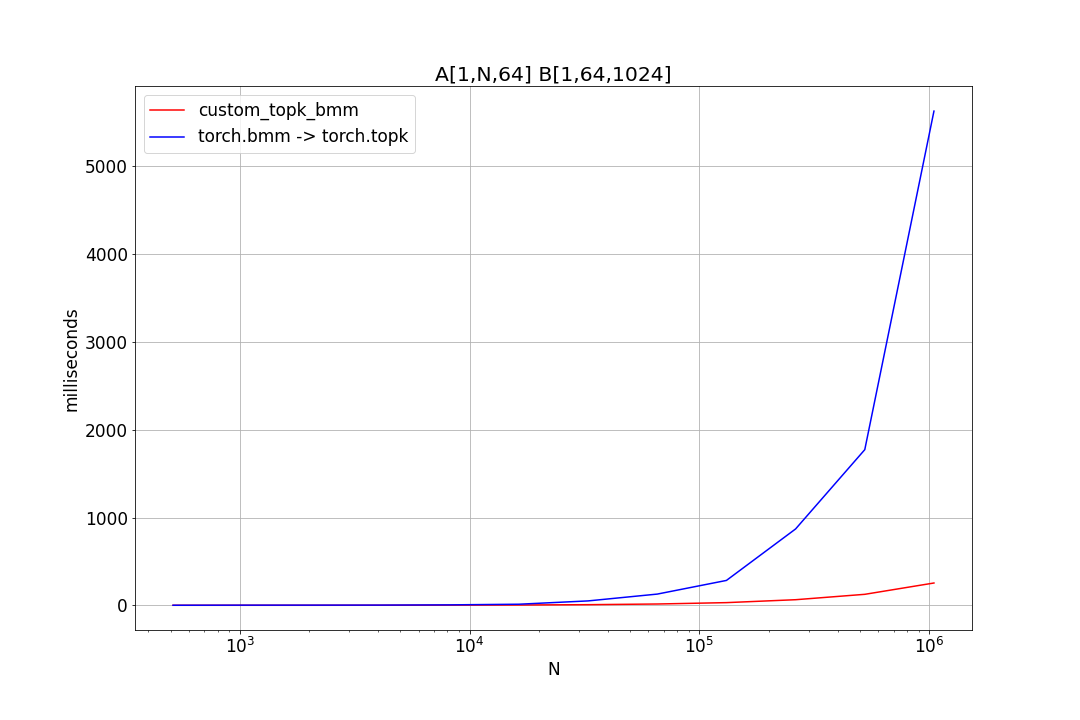
Runtime of fused TopkBMM vs. torch.bmm + torch.topk
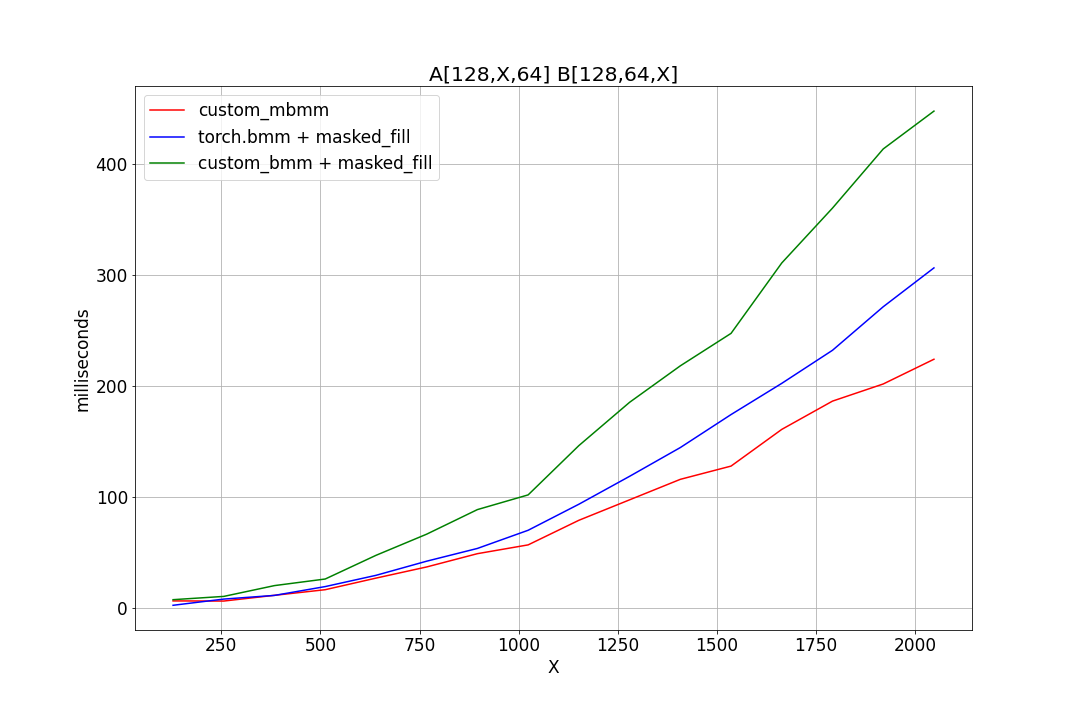
Runtime of fused MBMM vs. torch.bmm + torch.masked_fill
I also wrote a blog post about the motivation, applications and some implementation details of these kernels. The source code can be found in this repo.
I've been wondering for a couple years now. Why must the number of columns of the first matrix equal the number of rows of the second? I've been trying to look for an explanation for this but haven't found one. Does anyone know or can explain this to me?
First of all, I would like to say that I'm in no way good at math. I try to learn concepts when I need them for something else so I might be missing some prerequisite knowledge.
I'm currently learning about matrix multiplication and I just don't get why you need to transpose B if A is matrix with the shape of (p, m) and B is a matrix with the shape of (n, m).
To me it seems that if the length of the rows (the amount of columns) are the same in both matrices, the multiplication can be done row for row without having to transpose matrix B first.
I tried to multiply two equal matrices with the shape of (3, 4) without transposing the second and came up with the same result as doing it with the transposition.
Is it just a convention to do it the right way or am I missing something in the bigger picture?
I understand basic algebra and how matrix multiplication is done but why is it needed? I can't visualize it or come up with practical examples.
Hello guys, I am using ArrayFire library for signal processing. I am just curious about how to make more efficient my code. I read vectorization guide in docs, but i just ended up using gfor construct. Is it possible to improve efficiency ? Is there a better way for vectorization ? ( I hope there is :)
Note : I am aiming CUDA performance.
Here is the code which i am trying to improve :
#include <arrayfire.h>
#include <stdio.h>
#include <af/util.h>
static int proc_size = 1024;
static int fft_size = proc_size * 4;
static int staves = 288;
static int beams = 256;
static af::array S;
static af::array B;
static af::array R;
void fn()
{
gfor ( af::seq i, fft_size )
R( i , af::span ) = matmul( S( i , af::span ) , B( af::span , af::span , i ) );
}
int main(int, char **)
{
S = af::randn( fft_size , staves , c32 );
gfor ( af::seq i, fft_size )
S( i , af::span ) = af::randn( 1 , staves , c32 );
B = af::randn( staves , beams , fft_size , af::dtype::c32 );
R = af::constant( af::cfloat { 0 , 0 } , fft_size , beams );
try
{
af::setDevice( 0 );
af::info();
double time = af::timeit(fn);
printf( "Took %f secs.\n" , time );
}
catch (const af::exception &ex)
{
fprintf(stderr, "%s\n", ex.what());
throw;
}
return 0;
}
Just started recently with it at school.
Multiplying 2 regular numbers makes sense. 2*3 is merely 2 added to itself thrice
Adding 2 regular numbers? Makes sense too. 2+3 is incrementing the value of 2 with three
Matrix addition is also simple. You are basically incrementing the elements of the first matrix by the corresponding elements of the second matrix
But the rules behind matrix multiplication confuse me. Why SHOULD the numbers of columns of first matrix match up with the numbers of the rows of second matrix? Why do we multiply a row of the first matrix with each column of the second matrix? If 2*3 is 2 added to itself thrice, how does that work for matrices? How does one add matrix A to itself matrix B times?
The rules seem very arbitrary to me, and I am not able to understand it. I did search on the internet but a lot of the answers mentioned concepts and terms I dont understand and have not been taught yet like transformation and other things
Can anyone intuitively explain the concept and the rules of matrices multiplication to me? Why exactly is it done the way it is? Is there any specific reason or is it just plain definition?
Given two matrices A and B where A is an (m x n) matrix and B is an (n x p) matrix, with columns [b_1, b_2, ... , b_p], can the product AB be thought of as the matrix with columns
[Ab_1, Ab_2, ... , Ab_p]
I have this matrix
https://preview.redd.it/hw9vradmt6y61.png?width=106&format=png&auto=webp&s=bde91083ecca191748710a79ffe88a00776cf681
I need to end up with this matrix, i.e. multiply top row by 12 and bottom row by 20:
https://preview.redd.it/df14i8qst6y61.png?width=124&format=png&auto=webp&s=c34cc26a1d8951f22fb8d148985efc4c3e0663b4
How do i do this with matrix multiplication?
I am struggling to vectorize an inner loop in a matrix vector multiplication. The initial column-wise multiplication works well. However, I need a sparse version where I can skip 16x1 sub-blocks (i.e. the inner loop).
I suppose, I am running in a bunch of bound checks? Due to array_chunks, it should be guaranteed, that the inner loop are contiguous 16x1 blocks. Godbolt: https://rust.godbolt.org/z/fzn6n995d
I also tried a const generics version, which does not produce any assembly. Does anyone have an idea why?
Edit: as u/WafflesAreDangerous suggested adding a main() instantiates it. It generates no vectorized code either, even though there shouldn't be any bound checking since the sizes are known at compile time. https://rust.godbolt.org/z/MEovzc7sc
Edit2: The C version does also not the best job of vectorizing, however it does (obviously) no bounds checking: https://c.godbolt.org/z/4cPeacGqb
I'm trying to use the MMULT function on the Pearson spreadsheet, and it will only return one value in once cell instead of an array. I tried pressing control + shift + enter and it still returns one value. I have no problem getting it to work in excel. Any help would be appreciated!
I saw this hint in the 2015 day 10 megathread about using Conway's Cosmological Theorem to determine the length of N iterations of the look-and-say algorithm (yes, the same Conway that invented Game of Life that appears in many other AoC puzzles). But if that comment had any code to copy from, I could not find it; it was just the high-level overview. So, I got to re-discover how it worked for myself, and indeed it made a huge difference in performance!
My original implementation did what most solutions did: iterate over every single character to look for the repetitions to produce the string for the next round. And the fact that the string gets ~30% larger each round shows: computing just part 1 took 6.6s, computing part 2 extended the time to 1m30s, and then my code took another 30s just counting the length of the 2 computed strings (2m5s total runtime). Using m4's trace functionality, I determined that my code performed 37,990,946 ifdef(), 38,032,571 ifelse(), 44,980,837 pushdef(), and 8,017,641 incr() calls, plus 2 very costly len(). And trying to expand the solution to 60 iterations would be that much more painful.
But my new version is able to compute answers without ever expanding the string in memory! As Conway noted, you can set up a 92-element recurrence relationship matrix, where each row represents an element (a substring whose expansion will never overlap with the rest of the answer), and each column represents which other elements will be present after the expansion of the element. All the inputs I've seen happen to be 10-
... keep reading on reddit ➡If a have a 2 tensors say:
[[1,2,3,4,5],[6,7,8,9,10]] = matrix
matrix * matrix = x
How would I multiply this/ how does the process work to find a value for x?
I was never taught to write out matrix multiplication this way, maybe others have, but I came up with it independently recently when I was getting back into linear algebra. The key is that the top of the first matrix and the left side of the second matrix need to form a *square*. Writing out matrix multiplications like this makes them way more intuitive, including immediately knowing the dimensions of your output matrix, which is really useful in practice. It is also easy to extend for multiplying many matrices in sequence as well as left multiplying. Hopefully this helps you out as much as it did me https://blogs.ams.org/mathgradblog/2015/10/19/matrix-multiplication-easy/
I often wonder about the design of certain conventions in math, why they are the way they are.
For instance, with matrix multiplication, if you have a product of two matrices AB, why did they decide to make it the dot product of B's columns with A's rows?
If you transpose B, then the output is simply the dot product of each corresponding row. Doesn't that seem simpler? Why complicate things?
Well, it's probably not the most optimal way (especially if you're aiming for performance on bigger inputs), but I think it's pretty neat. The idea is as follows:
Then, asking for the number of possible adapter combinations is the same as asking for the number of distinct paths from the node 0 to the node representing the last adapter. This is where adjacency matrices come into play. An adjacency matrix M is a NxN square matrix where N is the number of nodes in the graph. The value for any element M(i, j) in the matrix is 1 if there exists an edge connecting the node i to the node j, and 0 otherwise.
Now, adjacency matrices have a very neat property: if you compute M^k, then M^k(i, j) becomes the number of distinct walks of length k between the nodes i and j. Since we cannot go "backwards", and since we have no cycles in this graph, this is the same as the number of paths, which in turn is the same as the number of valid adapter combinations that include k adapters. We can repeat this process up to the total number of adapters to obtain all possible combinations:
f = lambda i, j: j > i and lines[j] - lines[i] <= 3
m = np.fromfunction(np.vectorize(f), (n_lines, n_lines), dtype=int).astype(int)
aux = np.identity(n_lines)
sol_part_2 = 0
for _ in range(n_lines):
aux = aux @ m
sol_part_2 += aux[0, n_lines - 1]
tl;dr: you can solve day 10 part 2 by building an adjacency matrix, multiplying it by iself N times and adding the (0, N) element where N is the number of adapters.
Please note that this site uses cookies to personalise content and adverts, to provide social media features, and to analyse web traffic. Click here for more information.



{kind=link}
{kind=link}
{kind=link}