
Punstoppable
A list of puns related to "Perceptrons"
I'm attempting to tune a Multilayer Perceptron network in SPSS, and I'm looking under the Training Tab. There are two Optimization Algorithms, Scaled conjugate gradient and Gradient descent. Under Scaled conjugate descent, there are parameters called initial lambda, initial sigma, interval center, and interval offset. Under Gradient descent, there are parameters initial learning rate, momentum, interval center, and interval offset. I've done extensive research on how to tune these hyperparameters, and have found that the majority of papers use the default values for both algorithms. How can I go about tuning these hyperparams for my dataset? The documentation is lacking detail.
Hey all, Classifying 2 classes is doable with perceptrons in machine learning but, Is classifying more than two classes possible with perceptrons, such as three?
Like for example, we have a labels column in our specific dataset and we would like to classify them. We want to classify them into 3 classes, rather than two classes.
Which methods can I use for it? Is there any python code implementation(code snippets) or any idea?
Thanks for your ideas and suggestions
Haven't seen this one posted yet:
https://apps.apple.com/us/app/perceptron-an-idle-game/id1537908817
Not much to report yet as early progress is a bit slow, but there might be something to it as I'm getting some additional layers added to it as I reach the milestones.
Hi everyone, I am actually working on the implementation of CNN in FPGA using VHDL, but I am facing some issues such as:
Thanks
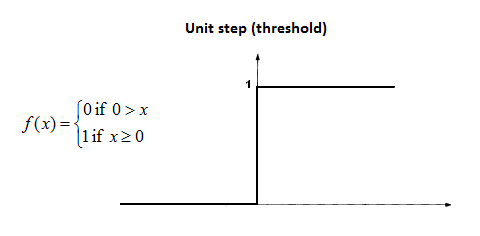
The most widely used neuron model is the perceptron. This is the model behind perceptron layers (also called dense layers), which are present in the majority of neural networks. Here is an explanation of the mathematics of the perceptron.
https://www.neuraldesigner.com/blog/perceptron-the-main-component-of-neural-networks
In his 1957 report "The Perceptron a Perceiving and Recognizing Automaton" the inventor of the perceptron Frank Rosenblatt writes:
"It is also useful to distinguish between mementary stimulus perceptrons and temporal pattern perceptrons - the latter having the ability to remember temporal sequences of events, rather than transient momentary images, such as would be obtained from a collection of isolated frames cut from a strip of movie film."
I was trying to do this last night and just don't know wtf to do. I found this repo that converts the IDX file format to a numpy array and saves the resultant image;
https://github.com/sadimanna/idx2numpy_array (I had to change 'imsave' to imageio.imwrite, and change some directories to fit my path)
So I've ran all that, and now have this directory full of these images. (When it was running, it'd say. `Lossy conversion from int64 to uint8. Range [0, 255]. Convert image to uint8 prior to saving to suppress this warning.` I assume this is doing the 'divide by 255` for me, in the preprocessing step, automatically?)
Anyway, so I have this data, and I have a Perceptron, here:
https://dpaste.com/2YPYRHNVG, also (basically the same code): https://dpaste.com/BC2DCGQLM
So I should have a numpy array, training and test data, and a Perceptron, so I should be good to go. Thanks for the help. Just kidding, I really don't know how to proceed from here. I believe I've set the weights and bias node properly (see updated dpaste below). Basically, I don't know how to interact with my Perceptron to proceed here, I don't know how to identify or load the targets, the data or how to run it.
Current Perceptron: http://dpaste.com/7KTT4B5L4
Previously I was doing stuff like what can be seen here, very basic and just copied from my book: http://dpaste.com/AXU8LYGHR
Would really appreciate someone holding my hand through some of this until I get rolling
TL;DR: Logistic regression and perceptrons seem really, really similar at first glance. But the more I think about them mathematically, the former seems all about projection onto the linear decision boundary, whereas the latter seem more about location relative to the boundary. This seems like a fundamental difference. Either one conception is wrong, or else there’s some equivalence between these conceptions that I’m not seeing.
Please forgive me while I flounder to put my thoughts into words. I want to understand the maths underlying neural networks, and to do so, I'm starting by trying to understand the relationships between the algorithms that came before. But I've hit a wall when trying to see similarities between logistic regression and perceptrons. I'll try to walk you through my thinking.
First logistic regression (LR). Studying the formula, LR essentially seems simply like a linear regression passed through a nonlinear sigmoid activation function. The activation function's purpose is to squash the linear regression's range between 0 and 1. This asymptotically bounded range allows us to interpret the LR's output as a probability, namely the probability that the input belongs to the positive class. Because we're just transforming a straight line to a squiggly one, I believe this can be interpreted as projecting the input feature vector onto the linear regression line (just like in linear regression), then compressing the range. Therefore, in LR, the output is a direct reflection of where the inputs fall on the line.
Second, perceptrons. Zooming out, perceptrons seem pretty much mathematically identical to LR, with one change: the activation function is not a sigmoid, but rather a step function. This means that whereas a LR's output will be a real value ranging continuously between 0 and 1, a perceptron's output is only ever 0 or 1 (or equivalently, -1 or 1), signifying whether the input is (1) or isn't (0, -1) a member of the positive class. Thus, the output of LR and perceptrons are analogous, except that because LR produces a continuous output, it also encodes the "confidence" of its classification decision, whereas perceptrons simply give you the decision.
Please stop me here if anything so far is incorr
... keep reading on reddit ➡I'm doing one of the assigments from Duke University Course - Introduction To Deep Learning
I'm trying to create a classifier with MNIST, but I dont want to use the Class implementation with nn.module, this is my code:
import numpy as np
import matplotlib.pyplot as plt
import torch
from tqdm.notebook import tqdm
from torchvision import datasets, transforms
import torch.nn.functional as F
mnist_train = datasets.MNIST(root="./datasets", train=True, transform=transforms.ToTensor(), download=True)
mnist_test = datasets.MNIST(root="./datasets", train=False, transform=transforms.ToTensor(), download=True)
train_loader = torch.utils.data.DataLoader(mnist_train, batch_size=100, shuffle=True)
test_loader = torch.utils.data.DataLoader(mnist_test, batch_size=100, shuffle=False)
data_train_iter = iter(train_loader)
images, labels = data_train_iter.next()
# Randomly initialize weights W
W1 = torch.randn(784, 500)/np.sqrt(784)
W1.requires_grad_()
# Initialize bias b as 0s
b1 = torch.zeros(500, requires_grad=True)
# Randomly initialize weights W
W2 = torch.randn(500, 10)
W2.requires_grad_()
# Initialize bias b as 0s
b2 = torch.zeros(10, requires_grad=True)
# Optimizer
optimizer = torch.optim.SGD([W2,b2], lr=0.1)
# Iterate through train set minibatchs
for images, labels in tqdm(train_loader):
# Zero out the gradients
optimizer.zero_grad()
# Forward pass
x = images.view(-1, 28*28)
# Linear transformation with W and b
z1 = torch.matmul(x, W1) + b1
A1 = F.relu(z1)
# Linear transformation with W and b
y = torch.matmul(A1, W2) + b2
cross_entropy = F.cross_entropy(y, labels)
# Backward pass
cross_entropy.backward()
optimizer.step()
correct = 0
total = len(mnist_test)
with torch.no_grad():
# Iterate through train set minibatchs
for images, labels in tqdm(train_loader):
# Forward pass
x = images.view(-1, 28*28)
# Linear transformation with W and b
z1 = torch.matmul(x, W1) + b1
A1 = F.relu(z1)
# Linear transformation with W and b
y = torch.matmul(A1, W2) + b2
predictions = torch.argmax(y, dim=1)
correct += torch.sum((predictions == labels).float())
print('Test accuracy: {}'.format(correct/total))
I know I'm just training the out layer parameters, the question is: How Can I Tra
... keep reading on reddit ➡One of the hottest topics of artificial intelligence are neural networks. These are computational models with the ability to learn from data. The most widely used neuron model is the perceptron. This is the model behind perceptron layers (also called dense layers), which are present in the majority of neural networks. Here is an explanation of the mathematics of the perceptron.
https://www.neuraldesigner.com/blog/perceptron-the-main-component-of-neural-networks
Please note that this site uses cookies to personalise content and adverts, to provide social media features, and to analyse web traffic. Click here for more information.





{kind=link}