How do you evaluate when analytic continuation is appropriate and if its going to give you consistent results?
I've got an ugly, complicated mess of a number-theoretic-optimization problem that seems like it can be beautifully reduced to something simple by using zeta function regularization, but my analysis background is all self-taught and if I were someone else reading my work, I'd immediately flag the argument as dubious.
As I understand it, its sort of never "ok" to manipulate divergent series algebraically--unless Ramanujan did it or it was done informally to simplify a complex argument and for some reason it comes out the same as the formal treatment and the two are consistent with each other. (sort of how its not "ok" to manipulate liebniz notation derivatives as algebraic objects--but it often works b/c they behave as linear operators and it usually (but not always!) looks the same as multiplication and division with division being the troublesome part)
Anyway, any guidance or resources you can give me would be fantastically appreciated.
I am struggling to understand how to make sense of how the plotting works re. Riemann's Zeta Function, and specifically using prime numbers.
Basically, every time I hear the phrase "zeta zeros", I get confused when trying to make sense of it all. There are the "trivial zeros" and the "non trivial zeros" for the "zeta zeros" I think.
As I understand it, there are these two interesting ways to plot the numbers.
-
Plotting points on the critical line with real value 0,5, inside the critical strip between 0 and 1. Presumably the plotted points are converging sums, taking the zeta function to infinity so to speak.
-
Plotting points, and interpolating them, creating a curved line that winds around origo, but crosses origo perfectly on every turn. This, as I understand it, the curve repeatedly connects to zero, or origo.
I wanted to figure out how to work with prime numbers in all of this, but, perhaps somebody please could comment on my notions for the two ways to plot the points and how it all makes sense. I know that there is something called 'analytic continuation', but how that related to the two ways to plot the points I wouldn't know.
I am curious to learn how to plot non trivial zeros on the critical line, but this can wait a little if there are other things I have to understand first.




What I mean is:
does a number x exist which satisfies:
ζ(x)=x (where ζ(x) is the zeta function)
and if so, is it trancendetal? or at least, what are some of the properties that it has?
It just seems really cool to me, and wolframalpha's answers don't really satisfy me because there isn't any infromation about them except their value.
Thank you☺



The sums [sum_{s=1}^\infty 1/n^s] appear frequently in basic calculus talking about convergence; they seem to be the prototypical example of series whose convergence can be (most) easily studied using the corresponding integral.
However, it looks to me right now to be a remarkable leap to extend this to the complex plane. Can someone illuminate Riemann's thought process, or was this move simply a stroke of genius that us mere mortals could not hope to ever reproduce?


With adding weight decay to the cost function I mean for L2: minimize(modelcost + lambda*weights^2)
Note: I haven't taken complex analysis yet, so correct me if I'm wrong on anything
Visually the circular arches and their symmetry around the line Re(s)=γ in the Reimann Zeta Transformation are probably the most prominent feature of the transformation. /u/direwolf202 provided a proof here as to why the graph appears to be symmetrical around γ. I believe the limit he references (lim s -> 1 (ζ(s) - 1/(s-1)) = γ) also illustrates another fact. Around the pole s=1, ζ(s) behaves very similarly to the complex function f(s)=1/(s-1) + γ. This behavior can also be explained by the Laurent series expansion of ζ(s). Since the Laurent series is based on the pole at s=1, ζ(s) can be approximated around s=1 using the first two terms of the series: 1/(s-1) + γ. As you get closer to s=1, the higher order terms of the expansion approach 0. I believe that the bigger circular arches created during the transformation are actually created by the 1/(s-1) term, while the constant term shifts the transformed grid to the right by γ.
I was able to confirm this by using manim to render what that approximation of ζ(s) looks like. Those arches look nearly identical to the ones in the Riemann Zeta Function transformation, except the area around the origin looks different. As for why those circular arches are created by vertical lines, I wrote a proof here. A similar method can be used to show how the horizontal lines become circles as well. Note that the radius of the circle created is inversely proportional to the distance of the line Re(s)=a from the pole s=1. So lines closer to s=1 end up creating larger circles after the transformation. I sort of think that the Riemann Zeta Function transformation might be a little misleading because that prominent symmetry is only really caused by behavior near the pole. The more distinct behavior of ζ(s) ends up getting squished to this small area by the origin. I don't think there's really a good way to avoid that though. I am unsure of why exactly f(z)=1/(z-1) seems to be symmetric around the origin though 🤔. Maybe someone could chime in on that.
EDIT: f(z) is a rational function, so I think it would be holomorphic every
... keep reading on reddit ➡https://swgoh.gg/p/197691866
We know that entropy regularization is used for promoting exploration. For A3C, entropy is used in loss and value function is estimate of accumulated external reward. For soft Q-learning, entropy is used as internal reward and value function is estimate of accumulated sum of external reward and internal reward. Does this difference impact much? Is there any paper talking about the differences?
Thanks!
In the neural style transfer paper, there's a style loss, content loss, and total variation (denoising) loss. The total loss for the optimizer is a weighted combination of these three losses. What's the difference between weighing multiple loss functions vs. adding e.g. L2 regularization?
In other words, when we say we're adding L2 regularization, are we just adding an L2 loss to the existing loss function?
I was looking at the formula for the reciprocal of the Riemann Zeta function and its Euler Product Formula here. The argument of the product on the RHS looks very similar to the infinite product of sin(x) used by Euler to solve the Basel problem. I don't know all the details about Weierstrass factorization, but Euler did use that idea of representing a function by multiplying (1-1/(n'th root)) for all the roots of a function. In that sense, the Euler product formula could be interperted as a special function evaluated at 1, with roots at p_n to the power of s like so. This of course has the following special case. Has such a function been studied before? What are some useful properties it may have?
EDIT: I elaborated a bit more in my response to cocompact.
EDIT2: With some help from Prime Obsession by John Derbyshire, I figured out the following series expression for it here
where omega(n) counts the distinct prime factors of n
In light of the recent post about donating flowers to put on Turing's statue in Manchester on his birthday, I thought I'd share this fun fact about my favorite academic.
Hi!
I've recently been using fminunc to try to solve an optimisation problem. The results are ok, but could be significantly better. The problem is minimising a non-linear (but convex) function, with an additional TV regularization term. Without the TV term the optimisation works perfectly, but when I add the TV term the result isn't as good as I'd expect (artifacts etc). I guess this is because the derivative of the tv isn't very enlightening, and is undefined at 0... plus a zero hessian everywhere.
I know there are a few codebases on mathworks etc implementing different TV algorithms, but they all seem to work only with very specific functions (often (y-x)^2+ TV(X) or something of that form). I haven't been able to find any that can work with an arbitrary non-linear function, so I was hoping someone may have some suggestions.
Fell down the youtube rabbit hole and think I have at least somewhat of an understanding of the RZF's relationship to the primes. Looking at this video, particularly at the end where they overlay a "wave" on top of a "modified prime counting function", it seems like at some point you could just look at where that wave jumps to determine every prime number. I'm sure this faulty logic, I'm just curious where the fault is.
Sidenote, the "wave" they overlay in that video, is that like a fourier series or is that something completely different?
Hello everyone,
I am not fully sure whether this is the right subreddit, but I hope so. Let me start by saying that I'm no mathmatician by training, I'm an economist, but I enjoy learning about math a lot. I've recently gotten interested in the Riemann Zeta-Function, which, I gotta say, is probably one of the coolest pieces of math I have found.
I've recently gotten into the topic a little and was glad to find an explanation on the analytic continution of the Zeta-Function on the entire field of complex numbers (sans {0,1}) via Riemanns functional equation that says: Zeta(s) = 2^s * π^{s-1} * sin(πs/2) * Gamma(1-s)*Zeta(1-s), which of course evaluated at s=-1 gives the well known result of Zeta(-1)=-1/12.
Now it is my understanding that Riemann's functional equation should hold true for all (except 0 and 1) complex numbers, so also for s=2. However, evaluation Riemann's functional equation as:
Zeta(2) = 4πGamma(-1)*Zeta(-1)*sin(π)
There I don't think Gamma(-1) exists (or is finite) and sin(π) is zero. However, clearly, Zeta(2) is well known as π²/6. For the formula to work out, we would somehow need Gamma(-1)*sin(π) = -π/2. How are we supposed to get that from there? In other words, how do we ensure that Zeta(2k), where k is a positive integer, does not become a trivial zero like Zeta at the negative numbers?
I'd be very curious for a discussion on this matter! Is Riemann's functional equation just only true for {s | s<1} \ {0}? So that the actual zeta-function should be piecewise defined as \sum_1^\infty i^{-s} is s > 1 and via analytical continuation for s<1? Help would be appreciated!
I've seen a number of educational youtube videos about the Reiman Zeta Function. I get the basics for how it works but I'm still a little fuzzy on why it's so important. The video-makers always say something to the effect of "it encodes certain information about prime numbers" but never go into any more detail than that.
So what does it tell us about primes and what are its uses beyond that as well?

{kind=link}
{kind=link}
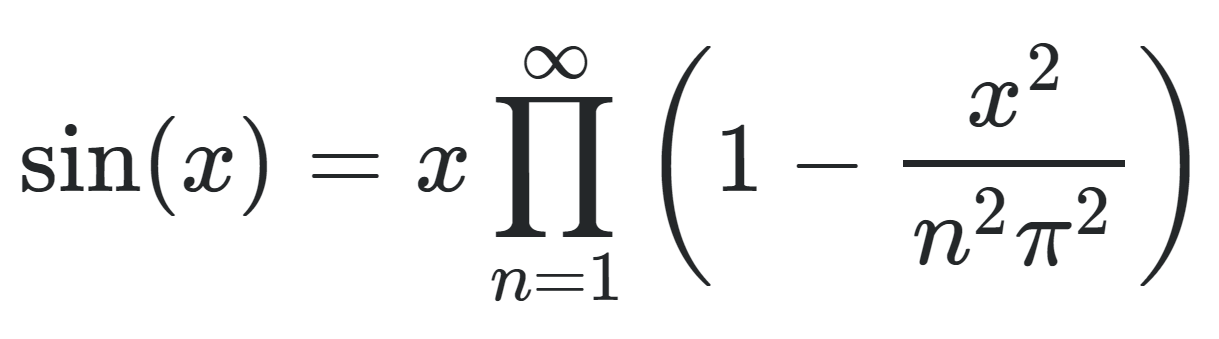{kind=link}
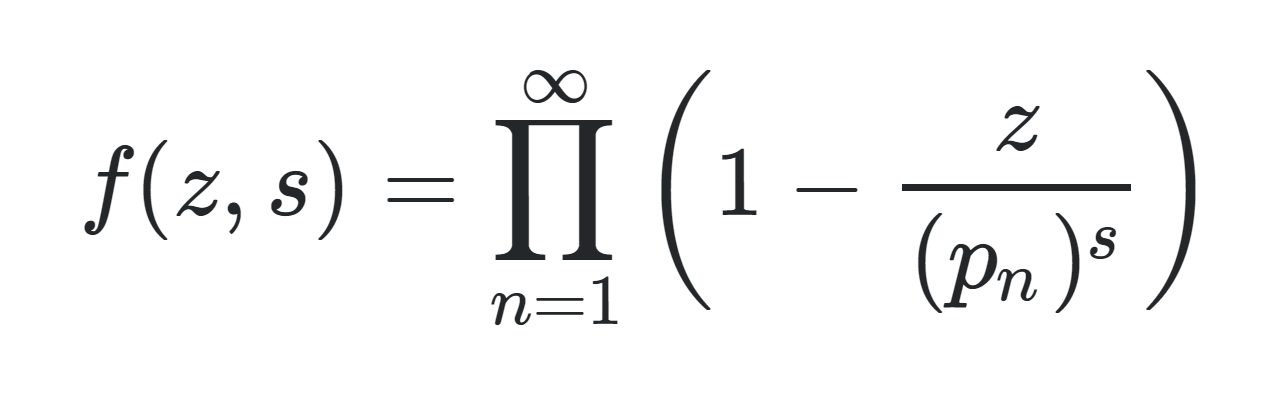{kind=link}
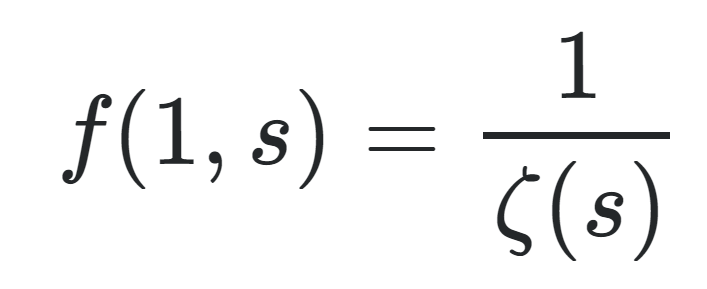{kind=link}
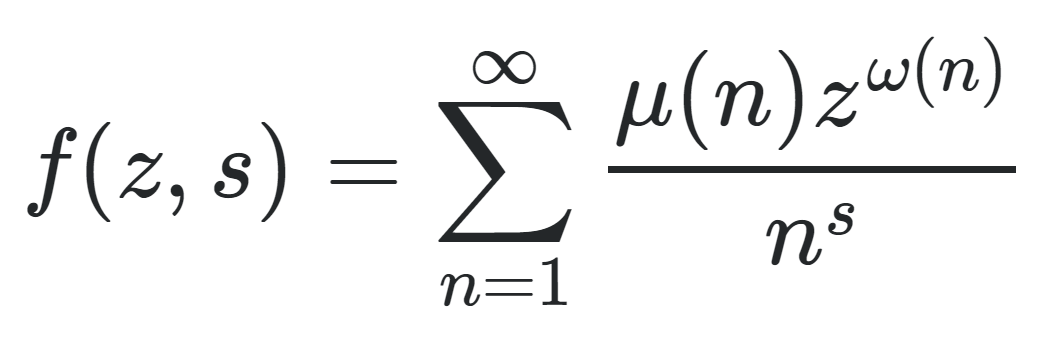{kind=link}