
Punstoppable
A list of puns related to "Prolog syntax and semantics"
Throughout this post, I might be (probably am) using the terms "semantics", "syntax", "geometric", and "combinatorial" in non-standard ways, which is why I have them all in quotes.
It seems to me that in general, problems (or systems) tend to exist on two separate levels. The "semantic" level is intuitive, approximate, not well-defined, vague, lacks form, etc. On the other hand, the syntactic level is well-defined, precise, and "mechanical" (though of course, one still develops intuition for the syntax).
Formalization involves "collapsing" semantics into syntax. You could also argue that it's "translating", rather than "collapsing", but the reason I say "collapsing" is that I don't think the syntax can ever correctly capture the semantics (i.e., there's always loss of information rather than an injective mapping).
Is there a field of math that studies formalization itself? (i.e., the process of turning semantics into syntax)? I imagine this is probably one of {model theory, proof theory, category theory}, but I'm a noob at all 3, so I wouldn't know.
This question isn't as pure-mathy as it seems. For example:
Consider traffic laws. Traffic laws are a syntactic manifestation of the more vague "semantic" system of: "don't get into collisions". Traffic laws are more "computable" (or verifiable) than the "don't get into collisions" semantic system. For example, being forced to stop at a stop sign is (for argument's sake) a sufficient condition on not hitting other cars going across the intersection, but it's not necessary (eg, if there's no other cars anywhere nearby, you don't actually need to stop to avoid hitting any cars). In this case, you could "relax" the traffic laws (i.e., bring the syntax closer to the semantics), but you may risk making the computability/verifiability harder. For example, suppose someone runs a stop sign and claims "well, I looked carefully both ways and there was no cars", that is harder to verify/"compute" compared to checking whether a vehicle stopped at a stop sign or not.
Edit: specifically, I'm wondering if there's a field that studies properties of the "mapping" from semantics to syntax. So, given some semantic system, let's conceive of the set of all possible attempts at formalizations of that system. Is there a field that studies the properties of these "attempts"? For example, one formalization is "stronger" than another if its syntax is able to prove more statements than the other.
Hey all! I only have a basic understanding of Syntax/Semantics (Hornsby and Fromkin); however, I was wondering what methods are used to determine which meanings get associated with which words. What are some of the theoretical positions regarding our methodology for determining meaning of meaning is arbitrary? Finally, how might these methods be employed with regards to a Generative framework?
Saw a video from YouTuber Tom Scott about Gender Neutral Pronouns and he mentioned a study about how Spanish and German speakers associated different adjectives to words dependent on their grammatical gender. "For example, the word “key” is masculine in German and feminine in Spanish. German speakers in the study tended to describe keys as hard, heavy, jagged, metal, and useful. Spanish speakers, on the other hand, used words such as golden, intricate, little, lovely, and tiny when describing keys. The word “bridge” is feminine in German and masculine in Spanish. Sure enough, German speakers described bridges as beautiful, elegant, fragile, pretty, and slender, while Spanish speakers said they were big, dangerous, strong, sturdy, and towering."
I looked into this study and it was never actually fully publishes, just mentioned in "Sex, Syntax and Semantics" from 2003 by Boroditsky et al. The study has been cited many times but seemed a little lacking in intellectual rigor.
There's also a published study disputing these claims titled "Key is a llave is a Schlüssel: A failure to replicate an experiment from Boroditsky et al. 2003" by Anne Mickan, Maren Schiefke and Anatol Stefanowitsch.
Is there any current consensus on this?
Is it correct that
Several programming languages may provide different syntaxes (not sure which plural word is proper) for the same piece in semantics (or the same piece in meanings). For example, C and Lisp provide different syntactic pieces to define a function (which I mean some meaning not its appearance). So we know that a Fibonacci function (which I mean the form) in C and a Fibonacci function (which I mean the form) in Lisp are essentially the same, because they represent the same thing with the same meaning, although they look different.
Books that teaches programming language theory create their own programming languages to cover as many pieces in semantics as possible, with their own syntaxes in order to avoid distraction of existing languages using different syntaxes for the same piece in semantics.
So is it correct that a programming language has a mapping which maps each piece in its syntax to a piece in its semantics (meanings)?
I am a bit loss in terminology. What are the terms for i.e. what do you call
Is a language construct exactly a piece in a syntax? Is the form of a function in C or Lisp a language construct?
Is a language feature exactly a set of pieces in a semantics? Is the ability of C or Lisp to provide syntactic way to represent functions (which I mean a meaning) a language feature?
Thanks.
Hi, folks, found a repo that implemented several Haskell language syntaxes and semantics in python. It is pretty interesting work.
What's a good linguistics book on syntax and semantics that covers the different approaches like generative grammar and generative semantics?
In Harper's Practical Foundations of Programming Languages (http://www.cs.cmu.edu/~rwh/pfpl/2nded.pdf), is it correct that types are not involved in "dynamics" (Chapter 5), but only in "syntax" (Chapter 1) and "statics" (Chapter 4) of a programming language?
Is it correct that types are not really a concept of semantics but essentially a concept of syntax of a programming language? (If I am correct, "statics" is part of syntax?)
Thanks.
In the dragon book
> 4.3.5 Non-Context-Free Language Constructs > > A few syntactic constructs found in typical programming languages cannot be speci ed using grammars alone. Here, we consider two of > these constructs, using simple abstract languages to illustrate the > difficulties. > > Example 4.25 : The language in this example abstracts the problem of checking that identifi ers are declared before they are used in a > program. The language consists of strings of the form wcw , where > the first w represents the declaration of an identifi er w , c > represents an intervening program fragment, and the second w > represents the use of the identi fier. > > The abstract language is L1 = {wcw | w is in (a|b)}. L1 consists of > all words composed of a repeated string of a's and b's separated by c, > such as aabcaab. The non-context-freedom of L1 directly implies the > non-context-freedom of programming languages like C and Java, which > require declaration of identi ers before their use and which allow > identi fiers of arbitrary length. > > For this reason, a grammar for C or Java does not distinguish among > identifi ers that are different character strings. Instead, all > identifi ers are represented by a token such as id in the grammar. In > a compiler for such a language, > the semantic-analysis phase checks that identi fiers are declared before they are used. > > > Example 4.26 : The non-context-free language in this example abstracts the problem of checking that the number of formal > parameters in the declaration of a function agrees with the number of > actual parameters in a use of the function. The language consists of > strings of the form a^n b^m c^n d^m . (Recall a^n means a written n > times.) Here a^n and b^m could represent the formal-parameter lists of > two functions declared to have n and m arguments, respectively, while > c^n and d^m represent the actual-parameter lists in calls to these two > functions. The abstract language is L2 = {a^n b^m c^n d^m | n >= 1 and > m >= 1}. That is, L2 consists of strings in the language generated by > the regular expression a b* c* d* such that the number of a's and c's > are equal and the number of b's and d's are equal. This language is > not context free. > > Again, the typical syntax of function declarations and uses does not >
... keep reading on reddit ➡A speech act has two orientations: from inside outward and vice versa, as follows.
From inside outward: When I wish to express a thought in speech, my thought is fed to the semantic component that outputs a corresponding semantic representation that is fed to the syntax component that outputs a corresponding syntactic representation that is fed to the phonological component that produces a phonetic representation that is then played out by my speech organs.
From outside inward: When someone tells me something by uttering a sentence, my auditory organs feed this sequence of sonoric signals to the phonological component that outputs a corresponding phonetic representation that is fed to the syntax component that outputs a corresponding syntactic representation that is fed to the semantic component that outputs a corresponding semantic representation that engenders a corresponding thought in my mind.
Let's consider a speech act oriented from inside outward. In an answer to a previous post of mine it was claimed that the pieces manipulated by the syntax component lack phonological content; this is the Late Insertion principle described on the first page of this document.
Now, let's assume, for the sake of simplicity, that the three components don't interleave, i.e. that the semantic component is activated only after the syntactic component has finished processing and produced an output, and likewise that the syntactic component is activated only after the semantic component has finished processing and produced an output. This assumption is not critical for my question, it just makes its statement simpler.
Then at the time the phonological component is activated, both the semantic and syntactic components have finished working and produced their respective outputs. Are both outputs available for the phonological component, or only the one produced by the syntactic component?
Take for instance the sentence "John's mother gave him a cake". Depending on context, it is possible to construe "him" as denoting John or as denoting some other dude. Assuming that the syntactic representation does not contain semantic content, the syntactic representation will be the same in both cases. Can the phonological component tell which is the
... keep reading on reddit ➡I think its best if I reword this specific question. I, for one, know that the Chinese room argument (CRA) shows that computers have syntax but a lack of semantics and genuine cognition that I or someone else is able to have. It follows 3 premises and one conclusion:
P1 programs are just purely syntax
P2 minds have semantic discretion
P3 Syntax is not enough for semantic understanding
C Minds are not just programmes
My question is how can you argue against the CRA showing that the CRA does have semantics
If yes and your looking for a Job don’t hesitate to pm Me
Hi, are there any expository survey articles/papers/books that talk about/introduce Syntax-Semantics interface?
I know nothing about it except for the term.
Thanks!
I've not learned much about it yet, but I've gained an interest in the distinction and relationship between Semiotics and Semantics/Syntax. Are there any philosophers that have worked on both, especially with a Phil. of Mind or Phenomenology bent? I haven't read much on Searle's work with language, but I'm thinking of using that as a jumping-off point.
I'm trying to setup a development environment based on neovim. rust-analyzer works pretty flawlessly, and I've found it's faster than when using VSCode.
I've also managed to port over (most of) my color scheme using the rust.vim and vim-rust-syntax-ext plugins, but it has some quirks fat I can attribute to the fact that they are based on dumb regex lookups.
rust-analyzer's syntax highlighting is really top notch in VSCode. One feature I really love is that types and traits can be highlighted differently.
Are there plans to include that level of syntax highlighting in other editors such as neovim?
/u/NeoDestiny You've repeated that idea using those words about 3 different times already (here's the latest one), so I can no longer ignore it as a simple slip of the tongue, and it's always grating to hear you say it cause it doesn't make any sense. Your definition of syntax is all wrong, syntax doesn't really care about lexical analysis of words, it cares about sentence structure (the rules and norms governing sentence structure and how they come about). So from the get-go, saying "stack enough syntax" already doesn't make any sense. What does it mean to "stack sentence structure"?
As for the meaning of semantics, you're in the ball park on that one, but I still want to clarify. Semantics is the study of "meaning" in language. What mental image you get when you hear the word "dog" is part of it, but it also cares about how words interact to change that mental image, and what rules it goes through and processes it follows to get to that mental image. Why I think your "stacking syntax gives you semantics" sentence still doesn't make sense is mainly because I still can't follow how you derive meaning (semantics) from whatever else you meant when you said syntax (lexicon?). Computers do have a semantic component in programming languages because they have to interpret what you wrote.
If you say "x = 5" in programming, the syntax will check that the sentence structure is correct (that the variable is on the left side of the assignment operator and that the value to put there is on the right side), and the semantics would take care to interpret that sentence into "make a space in memory available large enough to hold an integer, place the value '5' in there, and give the label 'x' to that space in memory". So yes, computers do use semantics all the time.
It all came from the "Consciousness, Robotics & The Human Mind - Debate with Fan" video, where the guy you were debating said a really dumb sentence right at the beginning: "a computer is something that manipulates syntax and spits out semantics". From that sentence I can tell you that the guy knows nothing about how computers work, because both syntax and semantics are involved in making a programming language; or how linguistics works, because of how he misused the words syntax and semantics. I really can't go deeper because I still can't figure exactly what you meant to say in the first place, but I wouldn't trust those
... keep reading on reddit ➡The syntax is the form and relation of the information, semantics is the meaning of the information. In the definition of semantics we just changed the word to another, semantics to meaning, we did not explain what semantics is. What is the meaning then?
Meaning is our personal experience of something. In this case, the meaning is subjective, opposition to syntax which can be defined objectively.
The Chinese room problem
In this classical philosophical thought experiment, we have a book with all the rules what the Chinese language has. We get Chinese symbols, and we can find an answer with the corresponding Chinese characters in the book to mimic the Chinese language. So we know Chinese. No. We just know the syntax of the Chinese language without any semantics of the characters.
Where the meaning come from then?
In vscode functions are colored different than variables. How can I do that in sublime? Is there an option in the lsp? Sublime only distinguish by syntax (eg. a function call, a function declaration, but not a variable of type function)
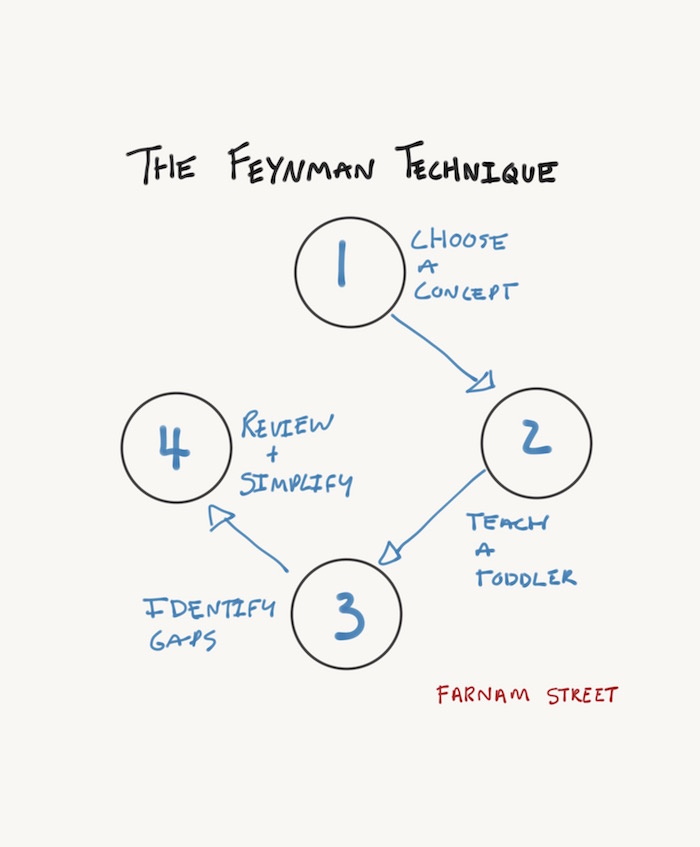
Feynman technique outline:
>1) Pick a concept
>
>2) Teach a child
>
>3) Identify gaps
>
>4) Review and simplify
Pulling from this post the meaning of syntax and semantics.
>Syntax is the grammar. It describes the way to construct a correct sentence. For example, this water is triangular is syntactically correct.
>
>Semantics relates to the meaning. this water is triangular does not mean anything, though the grammar is ok.
In order to transmit information from person to person it must have structure (syntax) and meaning (semantics), right? If you cannot emphasize structure then you must shift the burden from structure to meaning. A child has not been educated enough to understand complex structure. So by reducing the complexity you emphasize the meaning of what you are saying. The child likely doesn't know what many of the words mean. Thus, you must find a lower complexity representation of the terms that you want to convey. I am under the assumption that the child only has lower complexity understanding, not necessarily an equal but different circumstance.
For example instead of saying ,"A sinusoidal wave," you would have to say ,"Have you ever been to a place where there is a whole lot of water? Have you ever seen it flat? There are all these things that look like they are moving at the top, right? One of those things looks like something you would find on the street called a curb, but now imagine that it is made of water. Then imagine that there are many water curbs one after the other like a line you would walk down the halls in. And then....a wave.....interval....an example of that is something called a sinusoidal wave."
This again blows up the size of what you want to communicate, and thus the fourth step to review and simplify aids in reducing the amount that you are trying to communicate. Granted, it seems like a degree of interaction is necessary in order to understand what semantic/syntactic structure the child has in their head so you can build off of it. I suppose that is where the interactivity would come in if you were an instructor.
My question: Is this a valid representation of the Feynman method? Is presenting the problem of encoding information as a mixture of syntax and semantics valid, either? At which p
... keep reading on reddit ➡If I want to learn and do research in programming language syntax and semantics, could I just learn the "lambda calculus" and not any other programming language? And if so, I would appreciate it if you could recommend some books.
So I'm looking at semantic functions and we use this: f ( . ) : X → Y to represent them where X is a syntactic class and Y is a semantic class. Anything inside the brackets is syntax and anything outside is semantics. As an example it's given that the numeral "0" is syntax but the integer 0 is semantics. I don't quite understand what the difference between these is?
Hello,
I'm looking to learn some linguistics for a project I'm working on, but I'm not sure which sub-field of linguistics applies to my project. If I describe my project & what I'm trying to do, could someone point me in the right direction? I'm not just looking for a solution to my problem!
I have a video game which I've developed. The game has a simulated world full of objects, creatures, and other computer-controlled 'humans' for you to interact with.
I want you to be able to 'converse' with the humans in a more interesting way than just hearing them spit out a pre-written canned response, e.g. "the weather's nice". I'm not creating a chat-bot, I have no interest in parsing what the player types into the game, I'm mainly interested in a silent protagonist where other character talk at you.
The world & all the surrounding objects, along with the history of the world is all encoded in the game engine, so I have access to all that data. I also keep track of what each human 'knows' and 'wants'. I'm looking to take this data, and construct some semantic meaning from it based on the NPC's 'wants', then produce a syntax tree from that, which will get flattened into a (hopefully natural) sentence
Here's an example: a farmer lives in a village, and his crops are dying.
Given this data & the farmer's 'want', I'm looking to generate a sentence like 'Hello, could you get me a special fruit from the nearby forest to feed my plants?'
The problem is I don't know the best way to represent these concepts inside a computer. I have no background in linguistics. I believe that I'm talking about the field of 'semantics' within linguistics, and I've found a semantics reading list on this subreddit, but I just wanted to ask around before I melt my brain on the wrong thing.
Can someone point me to a relevant field within linguistics, & potentially some good resources? I'm alright at maths/logic/set theory etc, so I don't mind if a resource is heavy on these things.
Thanks!
The syntax is the form and relation of the information, semantics is the meaning of the information. In the definition of semantics we just changed the word to another, semantics to meaning, we did not explain what semantics is. What is the meaning then?
Meaning is our personal experience of something. In this case, the meaning is subjective, opposition to syntax which can be defined objectively.
The Chinese room problem
In this classical philosophical thought experiment, we have a book with all the rules what the Chinese language has. We get Chinese symbols, and we can find an answer with the corresponding Chinese characters in the book to mimic the Chinese language. So we know Chinese. No. We just know the syntax of the Chinese language without any semantics of the characters.
Where the meaning come from then?
Please note that this site uses cookies to personalise content and adverts, to provide social media features, and to analyse web traffic. Click here for more information.

{kind=link}