{kind=link}

A list of puns related to "Pearson's chi squared test"
I have three examples here:
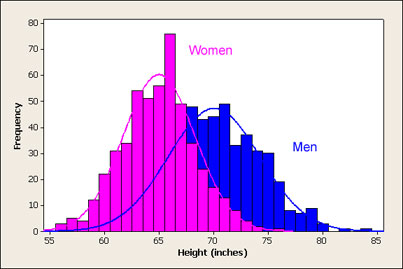
There are 3 different processes involved here. Now suppose we change the counts to get an unlikely result, which we want to use to reject the null hypothesis that heights follow a mix of two normal distributions with a mean male height of 5 feet 9 inches and mean female height of 5 foot 4 inches with normal distributions and respective standard deviations of 4 inches and 3.5 inches.
For example I make these changes to the data:
For the die throws, instead of 1000,1000,1000,1000 I add 200 to the first one so it's 1200,1000,1000,1000,1000,1000.
For the Benford distribution I add 200 to the second group to go from 301, 176 376, 125, 97, 79, 67, 58, 51, 46.
For the heights distribution I add a 20-foot tall dude to the mix, like this: https://imgur.com/a/skNlRDF
I think each of these three changes is enough for me to reject the respective null hypothesis. (In the first one I reject the hypothesis that it came from a fair die, in the second one I reject the hypothesis that it came from 2 normal distributions with the listed mean and standard deviation, and in the third one I reject the hypothesis that it came from a process that exactly follows benford's law).
Could you walk me through how I would actually get the exact pvalues in the three different cases? They are three different distributions and three different probabilities.
Besides requiring more computational power for Fisher's exact test, isn't it just a more superior version of the Chi-squared test?
So Pearsons Chi Squared Test tests whether differences in observations between categories (say A and B) occurs by chance. The way I interpret one of the assumptions of the test is that A and B must be drawn from the same sample or samples of the same size.
I need to do a similar test, but the samples that A and B are drawn from are different sizes (they are both drawn randomly, so there shouldn't be sampling bias). A and B can't be observed at the same time because of the technique. My initial thought is that I can use Fisher's Exact Test, but I don't know how this would be set up (not that familiar with the exact test families). Or is there a completely different test or adjustment for the Pearson's X2 test?
I have an exercise where I have to say if the statistic method used is the correct one and why, but I don't really get when I have to use one or another. These are the exercises:
https://imgur.com/gallery/BOHhDzn
https://imgur.com/gallery/RaFLmqA
https://imgur.com/gallery/lrjCoKX
Any help is greatly appreciated! 🙏
Trying to get a better understanding of how chi-squared tests are reported (what information should be included). I understand how to compute a chi-squared test (a hypothesis should be written, then calculate an appropriate test statistic, find the p-value, then reject or fail to reject the null hypothesis, an state the results). But generally speaking what information should absolutely be included when reporting the results? Aside from addressing the hypothesis, what other information is expected to be included?
I have a data set of 176 cases and need to examine the significance of an intervention which has two discrete outcomes. So I run the SPSS, and get this result where Pearson chi-square is 0.049, continuity correction is 0.075 and fisher's exact test is 0.056 (2-sided) & 0.038 (1 sided). And no cells have expected counts less than 5. So do I take the Pearson chi-square and report the test results as significant or do I take the continuity correction and Fischer's exact test and report as not significant. From a biomedical point of view what would be the ideal p-value to be reported here-?Pearson chi-square ? continuity correction ? fisher's exact test.
How often do you guys use Ttest, chi-squared, linear regression, or pearson correlation in either the analysis or presentation of data (MBB, Big 4, Boutiques)?
If you have a Phd or masters in either statistics or comp sci, dont answer since you probably use these all the time.
Hello! I am wondering what the correct course of action is when the assumption for a Chi Square test, that less than 20% of the cells in a cross-tabulation should have an expected count less than 5, is broken. I am using SPSS.
I have found conflicting answers to what to do next. Can I simply use the likelihood ratio that is listed below the Chi Square test instead? If so, can I also use the Phi or Cramer's V tests (for measuring the strength of the association) that derived from the data that violated the assumption in the first place? If not, how can I measure the strength of the association?
Also, I am confused as to the significance of the degrees of freedom and how they relate to the critical value. Is the critical value simply the level of significance, aka 0.05? The degrees of freedom is 6 (for both chi square and likelihood ratio), how does that change my findings? Should the degrees of freedom somehow be included in how I interpret or report the data?
Hope someone can help! Thanks :)
Hello all, I'm currently studying the Quantitative Analysis chapter "Hypothesis Testing". I understand z and t tests, but will there be any other tests such as Chi-Squared and F-Test on the FRM level 1 exam?
Hello guys, i'm doing segmentation of the population of Portugal for my master thesis on GIS and I've came across this phase in a segmentation paper:
"Graphical descriptions of the 12 clusters according to the original variables. On the graph of each variable, the cluster sections and remaining sections were compared. The bar representing the frequency of each modality has been given a more intense colour when the frequency in the sections belonging to the cluster is greater than that of those that don't belong to the cluster, to make it easier to understand. In this respect, the order of variables has been determined according to Pearson's Χ^2 statistical test, used to measure homogeneity."
After some research I wasn't able to find (or understand) the method for knowing the order of importance that each variable had to the clustering (if that makes sense).
Statistics isn't my field so if someone can point me in the right direction or advice some works i'd appreciate it, thanks!
I am researching the effect of an educational policy. A piece of research I encountered measured the effect of that policy on 5 different variables using chi squared test for independence at the 5% level. Two of these tests can back as significant.
A binomial calculation suggests that if you run 5 tests at the 5% level, the probability of 2 or more coming back as significant by random chance is about 1 in 4.
Is this a legitimate criticism of the statistics? Is it safe to accept that this policy was effective in 2 out of 5 metrics?
Thanks in advance.
I am doing a Pearson’s Chi-Squared Test to test to see whether or not the upload speeds of the new router compared to my old router. However, the issue is that there is usually limited variation in cases like this, because data speeds are also determinant on things like your internet package and etc. I am getting an average of 21.5 Mbps on my old router but my observed values are hovering around 25.8 Mbps, but the probability is like 20%. Is there any way to augment the test to account for situations that may have less variation than others? Thank you.
This is for a maths IA where I'm calculating chi squared but my expected and observed values are 0. in order to calculate chi squared, i'd need to divide by the expected values (0) but this is obviously not possible. would ignoring the these values be justifiable?
What is the recommended minimum total sample size for the distribution being tested? I see most of the examples online have a sample size of 100, but I wasn't sure if fewer samples could be used (the sample size of the population I'm testing is 51, and the "expected/control" sample size is 43).
What is the recommended minimum sample size of each category or class being tested? For example, when breaking down those two populations into the available categories for distribution, some are fewer than five to a category. I have heard that five is a good cutoff, in which case I would lump categories together appropriately to increase categorical sample size.
If either of the first two questions cause the chi-square test to be invalidated, particularly sample size, what test or approach should I look into?
Thanks for any feedback.
Edit:
Here is a text file with some raw output results using chi-squared goodness-of-fit.
So we have this cohort of tumors that also have samples of the associated normal tissue with them. For this particular analysis, I have divided these normal-tissue/tumor pairs into two groups: those that had the expression of a particular protein increase from the normal tissue to the tumor, and those that had the expression of the same protein decrease. From there, I'm looking at the distribution of other categorical characteristics based on these two sub-cohorts and trying to find any distinctions.
As for the text file, these sub-cohorts are indicated by the "Up" and "Down" in the column headers, and the different categories are the row headers. The numbers are the "counts" of each category in the cohort. For the analyses that happen to have cells with fewer than "5" in a category, a separate "truncated" analysis was conducted.
If anyone actually takes the time to get their head wrapped around it and has some suggestions for further statistical analysis (other, possibly better and/or more robust, tests in particular), I would greatly appreciate the input. Thanks again.
I have statistical data where I want to look at differences of frequencies with a Chi-squared test of independence. My main hypothesis includes 2 independent variables (gender, marital status), and I want to add another variable (country of origin) and look at its effect.
If this were a continuous variable I would use ANOVA and check for a statistically significant interaction, but since I am looking at frequencies I use Chi-squared. Is there a way to measure interaction in Chi-squared tests? Or should I use another test?
Thanks
In the examples I have seen in the literature the chi-squared goodness of fit test is usually used on least-squares estimates.
The use of this test seems to hinge on the observation that the least-squares estimate vector will, by definition, minimize the sum of squares of the residuals for each feature.
I believe shrinkage estimators like LASSO and ridge regression by definition do not always reach the minimum SSE (LASSO doesn't even have a closed form solution and is the solution of an optimization problem), but their objectives are still to minimize the sum of squared errors subject to their typical corresponding constraints on the norm of the estimate vector.
Therefore does it still make sense to perform a chi-squared goodness of fit test on a LASSO or ridge regression estimate? Or should another test be used?
There is a small discussion here, but they don't quite seem to come to an answer specifically.
For instance, if I wanted to find out if the age distribution of people at an event was reflective of population age distribution, could I group people by age (eg 0-4, 5-9, 10-14 etc) and then perform a chi-squared test based on the number of people in each age category? If not, what would be a better statistical significance test for this kind of application?
I’m doing an undergrad research project on vaccination rates of certain communities. I’m unsure if I can use a t-test for this since it’s more or less binary data (Y/N).
Would a chi squared test be more appropriate?
Essentially, I would take vaccination rates of Population 1 and 2 and see if there is a statistically significant difference.
Sorry if this is a bad question I’m a post bac student and haven’t taken statistics in over 8 years.
Link to the implementation: https://github.com/neeraj3029/chi-sq-test
One can run Chi-Squared goodness-of-fit tests on numerical data, or even see chi-squared statistics to check independence among two datasets with this package. 100% JavaScript.
Feel free to write issues in case of any questions/suggestions, or maybe share/star the repo so that it reaches more people!
So I would like to do a Chi Square test on the data set I have below:
| Group | Did not have visit | Had visit |
|---|---|---|
| 1 | 50 | 10 |
| 2 | 40 | 20 |
| 3 | 30 | 80 |
| 4 | 10 | 100 |
| 5 | 2 | 150 |
I want to see how significant the difference is for each group, but not sure how to go about it. My experience with r is very limited, so apologies if I'm missing information or not explaining correctly. Appreciate any help I could get.
Cross-posting this from r/statistics, I've realized that this sub might be more appropriate!
I have a research data set that consists of a number of videos, which we've manually coded using Themes and Sentiments, i.e. "Positive", "Advertisement", "Authority (gov. official, medical professional, etc). Each video can have any number of themes and sentiments coded to it.
We then, for each theme, did a pairwise, binary comparison with each other theme, to see if a theme has correlative value with another theme. In different terms, we took the set of videos that match a theme and the set of videos that do not match a theme, and paired them with the same binary sets on a different theme. Here's a made-up example matrix for one of these comparisons:
| Authority | Authority' | |
|---|---|---|
| Positive | 20 | 60 |
| Positive' | 30 | 260 |
My understanding is that we can find either the Phi Coeffecient, or the McNemar's Test Statistic to compare this data. I'm confused on which to use. My understanding is that:
Phi Coefficient is appropriate for unpaired, nominal data.
McNemar's is appropriate for paired, nominal, dichotomous data.
The comparisons above are nominal and dichotomous, but are they considered paired data? I'm having trouble reasoning about why they might considered be paired or unpaired.
As far as results go, McNemar's is giving results that match our hypothesis -- for instance, "Positive" and "Advertisement" show strong, positive correlation. When we take the phi coefficient, we are getting much weaker results (values closer to zero). The direction of the correlation is not different between any of our sets for the McNemar's and Chi Squared (Phi Coefficient) test.
p.s. McNemar's gives a directionless value from 0-1, and Chi Squared gives a directional value from -1 to 1, but we were able to multiply the McNemar's result by a direction derived from our results to show positive or negative correlation. I can explain how we did that if that's relevant to any answers here.
Hi All,
I have some questions regarding chi-squared goodness of fit tests, and the use of the quantiles for x^2 distributions table. I have a question that uses chi-squared goodness of fit tests. The test statistic value is 10.42 and the calculated degrees of freedom value is also 10.
From the question I can see that I look up the 10th row in the quantiles for x^2 distributions table to find which quantile my test statistic falls between. My question is, what drives the look up against the quantiles for x^2 distributions table? Is it the degrees of freedom value, or the test statistic value? As both values are 10 or 10.42, this is not obvious from the question?
I also don't see what the relevance is for calculating the degrees of freedom. This suggests to me that something is lacking from my understanding... :-) What am I missing here Reddit?
Thanks as always!
I'm doing some statistical research and I have two variables (young VS old couples) and 5 independent categories (5 levels of compatibility).
In my paper, I used the chi-square goodness of fit test to see how the observed vs expected (from previously known data) frequencies varied and was there a significant difference
Should I have used a chi square for independence to see is there a relationship? Or does it make sense I used both
What happens if the chi squared value is greater than the critical value? Will the null hypothesis be accepted or the alternative hypothesis?
I have an exercise where I have to say if the statistic method used is the correct one and why, but I don't really get when I have to use one or another. These are the exercises:
https://imgur.com/gallery/BOHhDzn
https://imgur.com/gallery/RaFLmqA
https://imgur.com/gallery/lrjCoKX
Any help is greatly appreciated! 🙏
I have a research data set that consists of a number of videos, which we've manually coded using Themes and Sentiments, i.e. "Positive", "Advertisement", "Authority (gov. official, medical professional, etc). Each video can have any number of themes and sentiments coded to it.
We then, for each theme, did a pairwise, binary comparison with each other theme, to see if a theme has correlative value with another theme. In different terms, we took the set of videos that match a theme and the set of videos that do not match a theme, and paired them with the same binary sets on a different theme. Here's a made-up example matrix for one of these comparisons:
| Authority | Authority' | |
|---|---|---|
| Positive | 20 | 60 |
| Positive' | 30 | 240 |
My understanding is that we can find either the Phi Coeffecient, or the McNemar's Test Statistic to compare this data. I'm confused on which to use. My understanding is that:
Phi Coefficient is appropriate for unpaired, nominal data.
McNemar's is appropriate for paired, nominal, dichotomous data.
The comparisons above are nominal and dichotomous, but are they considered paired data? I'm having trouble reasoning about why they might considered be paired or unpaired.
As far as results go, McNemar's is giving results that match our hypothesis -- for instance, "Positive" and "Advertisement" show strong, positive correlation. When we take the phi coefficient, we are getting much weaker results (values closer to zero). The direction of the correlation is not different between any of our sets for the McNemar's and Chi Squared (Phi Coefficient) test.
p.s. McNemar's gives a directionless value from 0-1, and Chi Squared gives a directional value from -1 to 1, but we were able to multiply the McNemar's result by a direction derived from our results to show positive or negative correlation. I can explain how we did that if that's relevant to any answers here.
Please note that this site uses cookies to personalise content and adverts, to provide social media features, and to analyse web traffic. Click here for more information.