
Punstoppable
A list of puns related to "Web crawler"
Hello,
Does DDG have its own web crawler and search index? Can someone please provide an abstract overview of DDG web crawler and search index architecture?
I want to browse funky stuff and find ARGs too
https://github.com/s0rg/crawley
features:
It's focused on flexibility and customization, and also works with any SPA framework, such as React.js, Vue.js and Angular, using Puppeteer to render the pages.
https://github.com/Tpessia/ssr-proxy-js
https://www.npmjs.com/package/ssr-proxy-js
For more info about SSR in general, here is a very good article about it: https://medium.com/@baphemot/whats-server-side-rendering-and-do-i-need-it-cb42dc059b38.
This may be a stupid question, but bare with me.
I’m trying to automate tasks at work, and much of that work is web research - sorting/reading through public documents, govt websites, etc and create memos for my boss and our clients to read over. This work is extremely tedious and much of my time is spent just searching for the information. So, I feel like there has to be a program that can help me skip the searching portion and just review the results.
My question is:
Are there consumer programs available that use a web crawler (or some equivalent mechanism) to automate an advanced keyword search, and compile the results in a Word Doc template?
If not, how many hours would it take an average developer to create such a program?
I know very little about programming, but I feel like there has to be some sort of tech out there that can scrape data for me so I don’t have to.
Work smarter, not harder. Amirite?
Thanks in advance.
Hello again,
I created another framework just for you, to ease your life and help you with your daily dose of scraping the internet!
It has a nice look and feel to it, try inspecting other web scraping framework examples available for Crystal and you will see what I mean!
When you write using Anonymous you feel like you are driving around a Mercedes-Benz vehicle, when you use something else to write your scraping logic you feel like you are driving a crusty Honda Civic.
Anyways thank you for your attention, feel free to contribute!
Behold the link to the GitHub page: https://github.com/grkek/anonymous
Does presearch crawl sites on its own and serve results based on this data? If it uses external search engine APIs, are there plans to wean off this and employ their own crawler & algorithm to serve results?
My concern is that reliance on third party engines is prone to service denial, should presearch become a large enough competitor. Could Google et al lock out search queries originating from presearch nodes and effectively bring down the ecosystem?
Can web crawlers reach pages that have no inbound links?
For example, say I create a "private" page on my webserver that isn't the index of the site, and has no links pointing to it.
Can it be reached by web crawlers somehow? Or is it un-indexable?
How do companies like Recorded Future and their competitors scrape and index Dark Web data? While I understand they use NLP to processes and categorize the data, how do they get it in the first place? For example, do they use scripts that work in a similar fashion as ones that would scrape the Clear Net? Do Dark Web (Tor) hidden services employ things like the robots exclusion standard? I’m probably just over thinking this…
I want to build a simple web crawler as a project, but I'm not sure where to start. Everything I'm trying to google wants to sell me something, have me download something, or just present the code to build it.
I want to know what a crawler does, how it processes dynamic sites, what to look for in terms of relevant links to follow, how to avoid ads. Is there a good resource for getting into web crawling that doesn't want to sell you something or do it all for you? Many thanks
All size websites considered. Message/ chat with url and data requirements for a specific quote
0.01 BNB refers to a single-page site.
Github with plenty of scraping experience https://github.com/coderpaddy
I can help you crawling data in exchange for XMR
**Platform(s):**This was a web game, which I believe was for school. It may have been its own standalone website, definitely wasn't attached to sites like Hoodamath or Coolmathgames. It was freely accessible online, because I played it at home.
Genre: It was part dungeon crawler and part-puzzle game I believe. There was definitely an educational aspect, so probably something to do with math.
Estimated year of release: I think I played it in 2010 but it could've very well been earlier.
Graphics/art style: It believe the background of the game and website was black, with the game being built off bright primary colors. The environment was in white and I believe it was top-down and 2D. Maybe tile based.
Notable gameplay mechanics: I believe you had to get a key of some sort, and there was stages/levels/floors. I believe there were enemies. I said dungeon crawler in the title but "maze" might be a more appropriate descriptor.
Other details: May have been fantasy/wizard themed. When I say this is a kid's game, I mean for very young kids. I couldn't have been beyond the 3rd grade. Looking through the subreddit, I found Fun School 6 Magic Land, which is similar but not it.
Suppose I have a standard landing page with a clear value proposition, visual, CTA, & social proof.
Now consider the following three scenarios for how I can host this landing page:
In all these three scenarios the content and HTML are exactly the same, so would the landing page score the same points regardless of which of the scenario?
TL;DR
Putting UX aside, does "good" CSS add any value to a landing page's SEO?
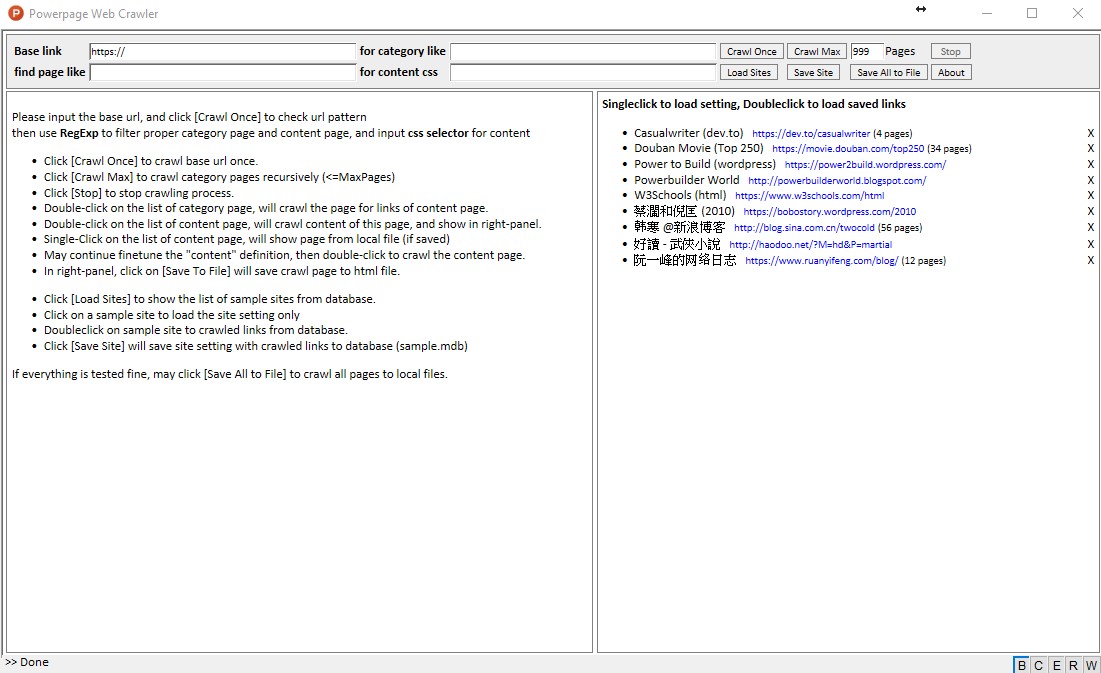
Just code a portable lightweight web crawler using Powerpage. Powerpage Web Crawler is a portable javascript-application running with Powerpage. It is coded by vanilla javascript in about 350 lines codes, without any dependency.
Powerpage Web Crawler is a portable program, just simply download and run powerpage.exe. It is a powerful and easy-to-use web-scrawler suitable for blog site crawling and offline-reading.
Just simply define below, for example
base-url := https://dev.to/casualwriter // the home page of favor blog siteindex-pattern := none // RegExp of the url pattern of category pagepage-pattern := /casualwriter/[a-z] // RegExp of the url pattern of content pagecontent-css := #main-title h1, #article-body //css selector for blog content.Program will
https://infinitysearch.co (try it out with the username demo and password demo)
We created this search engine with the goal of transforming how people search the web into a more enjoyable, customizable, and efficient experience.
We built this service using Flask for our web framework and Python for our web crawlers, which use some popular packages like Beautiful Soup and Requests.
Several of our projects are open source and on our Gitlab.
I built a web crawler in python years ago, to automate some osint stuff. Ive added to it over the years and it now crawls 600+ sites. I’ve posted this over in the osint sub but thought you guys may be interested. I’ve written an article on how you can build a similar crawler with a little bit of python and very little experience. Hope it’s useful :
I need a python script which scrapes the data of the website, it is just one website so there is nothing advanced or time consuming about it. The script should be able to run from windows command line and should take the website url as the parameter
Please message if you have any more questions or are interested in making the script. I am open to offers.
Payment will be made using PayPal
Thank you.
I realize this may not fit this sub, but I thought I’d try here anyway. This is probably a stupid question, but bare with me.
I’m trying to automate tasks at work, and much of that work is web research - sorting/reading through public documents, govt websites, etc and creating memos for my boss and our clients to read over. This work is extremely tedious and much of my time is spent just searching for the information. So, I feel like there has to be a program that can help me skip the searching portion and just review the results.
My question is:
Are there consumer programs available that use a web crawler (or some equivalent mechanism) to automate an advanced keyword search, and compile the results in a Word Doc template?
If not, how many hours would it take an average developer to create such a program?
I know very little about programming, but I feel like there has to be some sort of software out there that can scrape data for me so I don’t have to.
Work smarter, not harder. Amirite?
Thanks in advance.
It's focused on flexibility and customization, and also works with any SPA framework, such as React.js, Vue.js and Angular, using Puppeteer to render the pages.
https://github.com/Tpessia/ssr-proxy-js
https://www.npmjs.com/package/ssr-proxy-js
For more info about SSR in general, here is a very good article about it: https://medium.com/@baphemot/whats-server-side-rendering-and-do-i-need-it-cb42dc059b38.
It's focused on flexibility and customization, and also works with any SPA framework, such as React.js, Vue.js and Angular, using Puppeteer to render the pages.
https://github.com/Tpessia/ssr-proxy-js
https://www.npmjs.com/package/ssr-proxy-js
For more info about SSR in general, here is a very good article about it: https://medium.com/@baphemot/whats-server-side-rendering-and-do-i-need-it-cb42dc059b38.
It's focused on flexibility and customization, and also works with any SPA framework, such as React.js, Vue.js and Angular, using Puppeteer to render the pages.
https://github.com/Tpessia/ssr-proxy-js
https://www.npmjs.com/package/ssr-proxy-js
For more info about SSR in general, here is a very good article about it: https://medium.com/@baphemot/whats-server-side-rendering-and-do-i-need-it-cb42dc059b38.
https://github.com/s0rg/crawley
Main features:
I built a huge osint web crawler in python, to automate some osint queries, which has just been added too over the years.
I’ve written an article about how to make a basic one with very little coding experience. Hope it’s useful!
Please note that this site uses cookies to personalise content and adverts, to provide social media features, and to analyse web traffic. Click here for more information.



{kind=link}