
Punstoppable
A list of puns related to "Variance Covariance"
Is it as simple as adding Var(x)+Var(y)+Var(z)?
[Edit: Equation corrected. A more comprehensive example has been posted on CrossValidated.]
I am currently trying to recreate a matrix specification of a structural equation model (SEM) using the reticular action model (RAM) based on the example in Gerrard & Johnsons's (2015) Mastering Scientific Computing with R.
The RAM model is based on the McArdle McDonald equation:
C = F(I-A)⁻¹ [S(I-A)⁻¹]****^(T) F**^(T)**
Where
>C is the implied covariance matrix to be solved,
>
>A is an asymmetric square matrix of paths,
>
>S is a symmetric matrix that contains covariances (or correlations) and residual variances,
>
>F is a matrix that "filters" out the observed variables, and
>
>I is a variant of the identity matrix.
>
>-1 denotes matrix inversion, and
>
>T denotes matrix transposition
So, I am trying to solve C. However, while A, F, and I are matrices that can be specified, S relies on residual variances.
The residual variances and covariance matrix S
In the programming example, the S matrix has the following variables:
library(lavaan)
data(PoliticalDemocracy)
pd.cov <- cov(PoliticalDemocracy)
https://preview.redd.it/ctf5u1oliaj71.png?width=536&format=png&auto=webp&s=a7a20ad39e89aed70c6831a51d9b36da0225a89a
The book doesn't really explain where they get the values in matrix S, but it hardly seems they can be arbitrary. How can I obtain the residual variances and covariances in mat.S?
Video
Paper
https://arxiv.org/abs/2105.04906
Abstract
Recent self-supervised methods for image representation learning are based on maximizing the agreement between embedding vectors from different views of the same image. A trivial solution is obtained when the encoder outputs constant vectors. This collapse problem is often avoided through implicit biases in the learning architecture, that often lack a clear justification or interpretation. In this paper, we introduce VICReg (Variance-Invariance-Covariance Regularization), a method that explicitly avoids the collapse problem with a simple regularization term on the variance of the embeddings along each dimension individually. VICReg combines the variance term with a decorrelation mechanism based on redundancy reduction and covariance regularization, and achieves results on par with the state of the art on several downstream tasks. In addition, we show that incorporating our new variance term into other methods helps stabilize the training and leads to performance improvements.
Might be a fundamentally basic question but I am confused since I could not find one place where I could find the difference between covariance, correlation, variance and standard deviation.
An example to understand their purpose would be of great help.
Thanks a ton!!!
I understand that you can obtain the standard errors of the coefficients of a linear regression model by taking the square root of the diagonal elements of the variance-covariance matrix. For some reason, I just can't seem to see why that works. My intuition tells me that this should be really easy to grasp but apparently my brian is currently MIA. Can anybody ELI5 this to me please? Thanks!
Hi ! I'm looking for mathematical proof to show that Eigen decomposition of covariance matrix maximizes variance. I'm currently looking at this video (https://www.youtube.com/watch?v=cIE2MDxyf80) which is super useful to follow and gain intuition.
Can anyone explain why we choose the length of vector 'e' to be 1 ? I do understand how he uses Lagrangian but the vector 'e' is bound to unit length. Can anyone recommend where I could read up more about this specific topic ?
Thanks in advance !
Maybe this is a dumb question, but I'm in an investing class right now and I'm trying to recalculate beta myself instead of using factset data. Specifically, because we are looking at S&P 400 mid-cap industries, I am taking the beta of the industry vs the S&P 1500 composite as a whole.
Basically I'm doing: Covariance(S&P400 Industry, S&P1500 Index)/Var(S&P1500 Index)
I get reasonable betas, but my question is: Is this considered unlevered or levered? Since my beta is based on market prices, which are theoretically supposed to include all knowledge about debt/equity (according to the theory of efficient markets), would this be considered levered?
Edit: If it matters, I am using total return data from factset, NOT just price-return
Code here
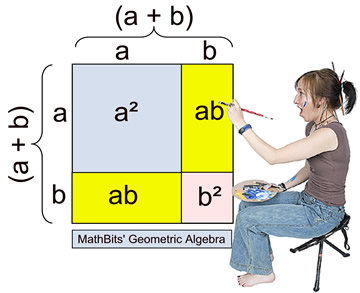
The expansion of VAR(X + Y) is related to the expansion of (a + b)^2 so I was hoping to be able to use a visual like this but I realized everything fits nicely into a square there because you are literally squaring the values and there isnt an analogous operation on variance that would work in 2D space
When studying a concept in stats, I really enjoy picking apart the equation that defines it. Thinking about a statistic mathematically really helps me understand exactly what that number actually represents, and how it relates both quantitatively and conceptually to other statistics.
I've recently been trying to do this with covariance, defined (for samples) as:
sigma[ (x-x_mean) * (y-y_mean) ]
--------------------------------
n - 1
I was struck to see that this is pretty much exactly the same formula as variance, except that rather than multiplying an observation's deviation from the mean by itself, you multiply it by the deviation of the second variable.
My question(s?) is, why do we multiply here? How should I interpret this relationship? What would it mean if we added instead of multiplied?
Understanding why we multiply in the case of covariance, I think, should also help me understand more deeply what the variance statistic (sigma^(2)) represents too.
Given the success of SELUs with standardized data, I’m wondering if there is an equivalent for whitened data. I.e. is there an activation function that preserves the mean, the variance and the covariance between each variable? I don’t know if it’d be useful, but the data I have for my FFNN has very high covariance between a lot of the variables, so I figure whitening could be useful, and maybe preserving it across layers could be too? I think the main advantage of SELUs was that the gradient magnitude remained somewhat constant, so I don’t imagine this would be nearly as useful, but I’m wondering if anyone has looked into it.
I've found the correlation matrix using the data analysis toolkit to help me find the variance of a portfolio of stock returns. However, in all the YouTube tutorials I see people using this variance covariance matrix which isn't in the toolkit. What is the difference between the two and how should I alter the correlation matrix to find the variance covariance matrix? Thanks
So I've come up a cast an issue where the compiler is telling me I can't do something that I think I should be able to do. I've simplified it down and the code is below
class Program
{
static IEnumerable<BaseInterface> GetSubInterfaceImplementers<T>()
where T : BaseInterface
{
return new GetThings().OfType<T>();
}
private static IEnumerable<BaseInterface> GetThings()
{
return Enumerable.Empty<BaseInterface>();
}
}
public interface BaseInterface { }
public interface SubInterface1 : BaseInterface { }
public interface SubInterface2 : BaseInterface{ }
So this line return GetThings().OfType<T>(); is giving me this error:
> Cannot implicitly convert type 'System.Collections.Generic.IEnumerable<T>' to 'System.Collections.Generic.IEnumerable<StackOverflowQuestions.BaseInterface>'. An explicit conversion exists (are you missing a cast?)
In short it is saying it cannot cast IEnumerable<T> to IEnumerable<BaseInterface> even though I explicitly said T must be of Type BaseInterface.
If in that method I change the code to read like this
return GetThings().OfType<SubInterface1>();
It compiles so it clearly doesn't have an issue returning a sub type thanks to IEnumerable being 'Co' or 'Contra' variant (I can never remember).
So why wont it compile??
Explicit casting works, like this:
return (IEnumerable<BaseInterface>)GetThings().OfType<T>();
but why can't the compiler infer it
The estimator for generalized least squares is given by this equation. What function and how should I use if I know the Ω variance matrix (as well as X and y)? Where in lm or glm should I input this?
Hi experts,
I'm working on my homework. How do I calculate Variance Covariance Matrix with SUMPRODUCT of deviation from mean values?
Screenshot Context: https://gyazo.com/ba48851cda318e7018b423b67a5d5710
I'm not even sure if I calculated my sumproducts properly... I belive I am supposed to SUMPRODUCT(medianSat, medianSAT) for MedianSAT cell... and when it's Acceptance Rate x Median SAT I would do SUMPRODUCT(acceptance rate, Median SAT) ... which gives -267.8008
I know what is a covariance matrix what are eigenvectors and what are the principle components. By definition, principal components are the directions of the data which have the highest variance, but in practice, in order to find those directions, we calculate the eigenvectors of the covariance matrix. Why?
I am seeing a ton of examples that use a correlation matrix, but the formula for portfolio variance uses covariance. What is correct here and why?
Portfolio variance = (weight(1)^2variance(1) + weight(2)^2variance(2) + 2*weight(1)*weight(2)*covariance(1,2)
When finding the variance for ---> Var(4X - Y), when and why would you use this formula --> 16Var(X) + Var(Y) - 4Cov(X,Y) instead of this formula --->16Var(X) + Var(Y)?
Hey, I have a problem in which I have to do a regression for 3 variables with just the mean/median and the variance/covariance matrix (also have n). I only worked with raw data before. Any tips on how I can get ß0, ß1, ß2 and the respective standard error?
There are 2 scenarios, one with simple regression (bivariate) and the other one with all variables for a multiple regression. The last is where I'm struggling the most. OLS method is used.
Any help would be greatly appreciated :)
I'm assuming that I need to calculate the p-value for these items but I'm at a loss in the knowledge required for this. Would different formulas be needed for each of the values in this matrix?
Topic. So...
Take data > zero-center > scale, and keep in mind that scaling will affect results > calculate covariance matrix > calculate eigenvalues and associated eigenvectors.
Wikipedia's page on PCA says: >Each eigenvalue is proportional to the portion of the "variance" (more correctly of the sum of the squared distances of the points from their multidimensional mean) that is correlated with each eigenvector.
I'm struggling to understand why this is true.
Any ideas?
Thanks!
Hi ! I'm looking for mathematical proof to show that Eigen decomposition of covariance matrix maximizes variance. I'm currently looking at this video (https://www.youtube.com/watch?v=cIE2MDxyf80) which is super useful to follow and gain intuition.
Can anyone explain why we choose the length of vector 'e' to be 1 ? I do understand how he uses Lagrangian but the vector 'e' is bound to unit length. Can anyone recommend where I could read up more about this specific topic ?
Thanks in advance !
Please note that this site uses cookies to personalise content and adverts, to provide social media features, and to analyse web traffic. Click here for more information.


{kind=link}
{kind=link}