
Punstoppable
A list of puns related to "Bottom up parsing"
I made a playlist of classical albums that have been in my library for at least 2 years, and have less than 2 plays. This is about 9300 tracks. What I want to do is run a shortcut that presents a list of composers, then after selecting one of those, a list of albums with music by that composer on it. I pick an album from that list and it plays the album from the beginning.
I have it all working; however, it takes about 3.5 minutes to generate the list of composers because it has to cycle through all 2500+ dictionaries to pull the data for the lists. Is there any way to do this faster?
FYI: I'm stupid at dictionaries and just barely above stupid at shortcuts.
Here's a version of the dictionary parsing part: https://www.icloud.com/shortcuts/4ff2a5d34dff4b31a149e5892d25e715. I put the JSON dictionaries in a text field at the top; but, in my version, I load it from a file on iCloud Drive. Beware: if you run it, it's going to take a while to complete.
I am trying to parse through some XML files that are in the size of up to 10gb files.
I have tried parsing using XML ElementTrees parseIter as well as lxml iterative parsing as loading these directly into memory doesn't feel like the best way to go about it.
The end goal is to get a bunch of this data into some SQLite database (because querying an SQL database will probably be much faster and easier, and for a local solution that doesnt need many of the features that other SQL solutions like PostgreSQL or even using a NoSQL solution)
The problem is... Just parsing through the XML file takes forever, I'm testing it on a smaller set of data but it's still over 4 hours and not finished
Is there some way to improve the speed of this process? Also, when I get my desired data, should I execute inserts one at a time or build a query string to insert every 1000 lines or something? What would be most optimal?
I'm not sure if it's possible to speed things up by trying to multi-thread the operation, I've got limited experience for this.
Any ideas or suggestions are welcome, even if it's telling me that this idea is wrong! Thank you!
I thought I'd post my write up and code for using Python to drive an investment strategy based on monitoring and parsing an SEC (Security Exchange Commission) database in case it helps any beginning algorithmic investors out there! The code involves parsing both XML and RSS feeds, automatic emailing and texting, and portfolio monitoring.
I would love to hear any thoughts you have on the code itself (its gotta be terribly inefficient), the strategy, or any tips for improvement! This is my fourth major project, so I'm still quite the beginner.
Link to the write up:
http://hofdata.com/2016/03/18/investing-with-python/
Link to the complete code:
https://github.com/ericlighthofmann/EdgarScrape/blob/master/edgar_email.py
No real backstory, I just needed to see where the walls were for my python client and noticed that it looked pretty neato-burrito. Here's a few of the maps for your viewing pleasure.
Edit: If you're looking at this on your phone, it probably won't look right.
#############################
## ##
# #
# #
# #
############### ###############
# ## ## #
# ################################# #
# ||||||| # ||||||| #
# P ||||||| ||||||| P #
# _ ||||||| ||||||| _ #
# ####### ####### #
# X #
# X #
# X #
# _ ######## ######## _ #
# # # #
#|||||| ### ### ||||||#
#|||||| ### ### ||||||#
# X X #
# # + + # #
# # + # ? # + # #
# # # # # #
#? #### #### ?#
###### ######
# #
# X #
###############################################
##Geokoala
##### #####
########xxx## ##xxx########
##O x# #x O##
## _ x# #x _ ##
It hurt like hell, but my farts smell great.
We are extremely happy to welcome /u/parsing_trees to our mod team. PT has been an amazing contributor to this community, sharing his time and his knowledge with us and we very excited to have him working with us to better this sub and bring some cool new features out.
Welcome aboard PT :)
I have around 1000 PDFs of roughly 1000 pages each, and would like to do text analysis. I therefore need to extract the text into a string, which I can then split in senteces/words etc.
I have tried PyPDF2, and while everything is working as intended, the result is not satisfactory as words are often extracted with no space between them, and the text generally isn't very "clean".
EDIT: I really love reddit, thank you so much for all the answers, read every one of them! I made tika work in a new conda environment, and this has produced results that are just good enough for the task at hand - I might return to this later as I am sure other methods of parsing could give even better results. Thank you!!
Anyone have experience with effective ways of doing text extraction from PDFs?
Happy Holidays from http://www.SideloadVR.com!
We have upgraded our Amazon EC2 instance to handle the increased load. This should reduce the build time for an .apk. However, the downloader in the Android app is not that sophisticated and when the internet connection is unstable (which most are without people even noticing), the download gets corrupted and a "Parsing Error" will be thrown.
Two ways to fix that:
try again. The moment the build phase is done, it's really just hoping you get the file in time before a package drops.
if you have access to the original apk (i.e. StreamTheater), then download and use the standalone injector (also on SideloadVR.com)
Our EC2 instance is located in West of the USA and you can try pinging 54.201.16.115 to see if you get dropped packages.
Also, if you have problems setting up your signature (either automatic or manual), try the manual setup using the mobile Chrome browser. We are suspecting that the Samsung Internet Browser is truncating uploaded signature files. If all doesn't help, setup the signature manually on your computer and upload it here: http://54.201.16.115/apkbaker/uploadID.html
SideloadVR is a free project solely funded by donations. We wish we could spend more time on development to improve the Android app, etc, but currently we are in the crunch to finish our games for Rift and Vive launch. Until we have some time or money to hire additional programmers, we hope you patiently retry the download if you get any parsing errors :).
Cheers,
Mark from http://www.SideloadVR.com
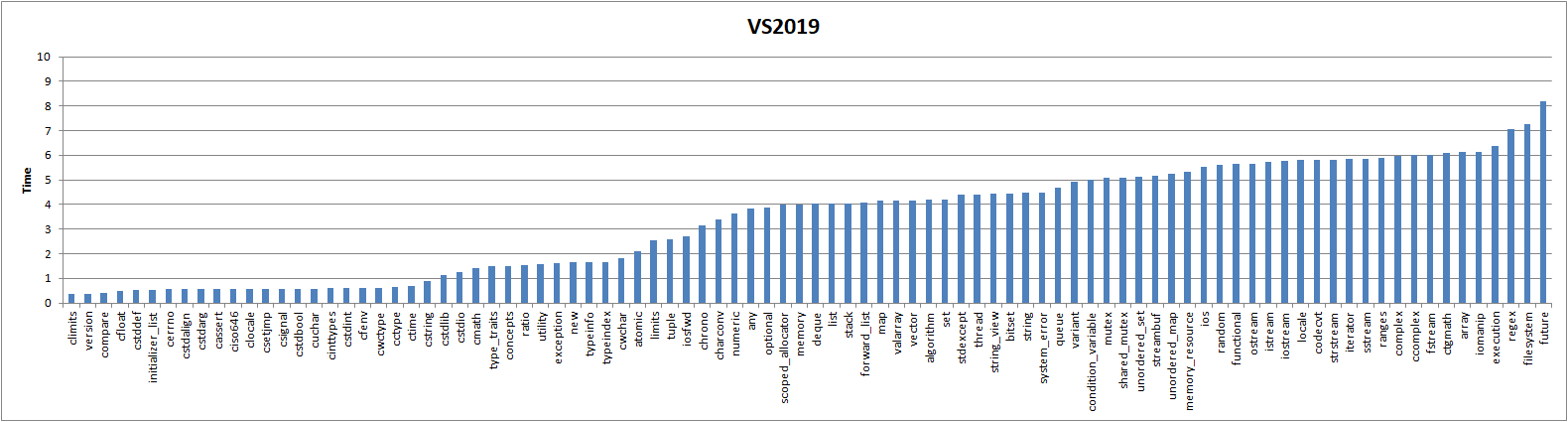
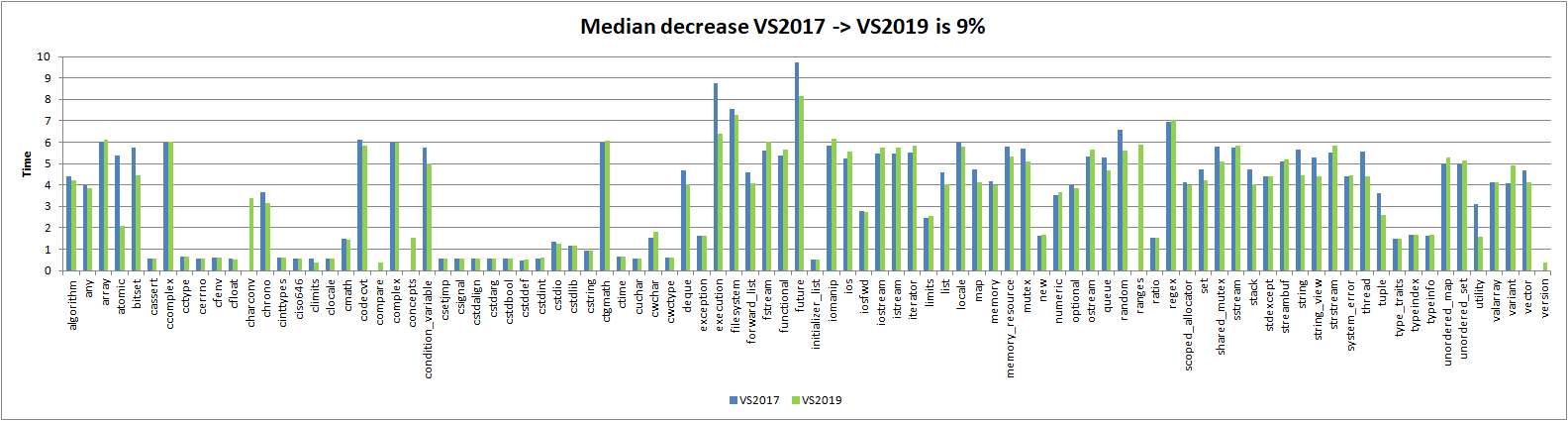
One of the MSVC devs poked me to update the results from https://www.reddit.com/r/cpp/comments/860hya/stl_header_token_parsing_benchmarks_for_vs2008/ for VS2019:
Graph of VS2019: https://raw.githubusercontent.com/ned14/stl-header-heft/master/graphs/msvs-2019.png
Comparative graph: https://raw.githubusercontent.com/ned14/stl-header-heft/master/graphs/msvs-history.png
Detailed notes: https://github.com/ned14/stl-header-heft/blob/master/Readme.msvs.md
Project github: https://github.com/ned14/stl-header-heft
There is a lot of good news in this benchmark: overall VS2019 has 9% lower token processing times than VS2017 did. That makes VS2019 almost as quick as VS2008 used to be!
The single biggest surprise is surely now <array>, which is by far the biggest impact STL container now that Microsoft have greatly improved <string> and especially <vector> and <forward_list>.
I'll try to produce updated benchmarks for libstdc++ during this coming week.
I'd like to take this opportunity to thank the Visual C++ team for such outstanding work on slimming down their STL implementation, yet simultaneously implementing a large proportion of C++ 20! Great work guys, wish more STLs were like yours!
Full Statement
From 1-12 top to bottom this team this roster has sacrificed so much for our nation. our summers, our bodies, our mental. We came up short can’t nobodies more upset than us but I refuse to tolerate any Slander for our play you cannot question our heart
Our character, or are spirit we layed it all out on the line each and every game. Don’t disrespect us this coaching staff or USA Basketball as a whole but respect the world basketball is an international game these countries are talented
JB, Khris, JT, Dmitch, Mason, Marcus, Kemba, D White, BrooK, HB, Joe it’s been an honor I’d go to war with any of these fellas any given night. #Godspeed fellas let’s head home with a Dub 🇺🇸
We’re also the ones who stepped up to the plate when others stepped down. We qualified our nation for the Olympics we got some work to do to rebuild a legacy that was left before us were on the wrong side of history indeed. But that’s gunna make the next medal that much sweeter!
https://twitter.com/Original_Turner/status/1172142615514492930?s=19
A few notes before we get started:
This is 68 episodes of It's Alive. I could not find Going Places on the website.
I may have made errors trying to copy and paste everything into 1 test document.
Transcripts were definitely done by a different person on different episodes. One will use Vinny (said 498 times), and others use Vinnie (128 times).
Lets first go through the Brad Leone Bingo card:
a) Oh no - 39
b) Vincenzo - 19
c) I believe - 25
d) garlic - 193 / allicin - 17
e) Fermentation station - 15
f) Vessel - 24
g) Bad boy - 51
h) Cut that - 10
i) "water" - 256 / wourder - 4...
j) Who's better than - 11
k) Beautiful thing - 15 (Beautiful - 153)
l) It's been - 39
m) Big boy - 45
n) End of the day - 23
o) Upsize down - 4
p) Fact check - 7
q) I wish you guys could smell - 5
r) Good boy - 31
The ones I wanted to check:
Sumac - 10 (lower than I thought)
One shot one Kill - 11
Delaney - 11
Botulism - 10
Goobalini - 5
edit: landing zone - 5
If you have any other suggestions, here is the text document to..... enjoy: https://drive.google.com/open?id=1qRs861ybJM1AOPwgQ5lA8bDbU4NddHwb
I can barely walk, but every time I fart the room smells great!
I thought I'd post my write up and code for using Python to drive an investment strategy based on monitoring and parsing an SEC (Security Exchange Commission) database in case it helps any beginners/intermediates looking to do a similar project! The code involves parsing both XML and RSS feeds, automatic emailing and texting, and portfolio monitoring.
I would love to hear any thoughts you have on the code itself (its gotta be terribly inefficient), the strategy, or any tips for improvement! This is my fourth major project, so I'm still quite the beginner.
Link to the write up:
http://hofdata.com/2016/03/18/investing-with-python/
Link to the complete code: https://github.com/ericlighthofmann/EdgarScrape/blob/master/edgar_email.py
Please note that this site uses cookies to personalise content and adverts, to provide social media features, and to analyse web traffic. Click here for more information.















{kind=link}
{kind=link}