
Punstoppable
A list of puns related to "3d Pose Estimation"
https://reddit.com/link/qhbrdm/video/usqhai2og3w71/player
---
For more exciting developments like this, follow CatalyzeX on twitter, and add our browser extension to easily get code for machine learning / AI papers anywhere!👇
Chrome: https://chrome.google.com/webstore/detail/aiml-papers-with-code-eve/aikkeehnlfpamidigaffhfmgbkdeheil
Firefox: https://addons.mozilla.org/en-US/firefox/addon/code-finder-catalyzex
Hi everyone! :)
One of my former students developed a very cool point cloud labeling tool, called labelCloud! The tool provides smooth labeling interaction with 3D point clouds to support users in generating training data for #3DObjectDetection and #6DPoseEstimation.
labelCloud is publicly available, easy to install, and simple to use. Check out our github: https://github.com/ch-sa/labelCloud
If you give it a go, we would be more than happy to receive your feedback on it. So, as we are currently evaluating it, we invite you to fill this short questionaire https://forms.gle/moEyjGSa1Eiiq7VT8 (~5 min)! Thanks in advance! :)
Further information can be found in our paper from CAD'21 conference: http://dx.doi.org/10.14733/cadconfP.2021.319-323
Hello guys!
I am working on a problem that requires estimating the 3D rotation and translation of an object with respect to the reference camera. Please find below details on the expected input and output of the pose estimation algorithm.
Can anyone please help me out and guide me on how I can achieve this??
https://preview.redd.it/jduifqo8s6d71.png?width=581&format=png&auto=webp&s=9d98bdf1c4b9919c3211151973653345d0dc4364
Expected Input:
Solution/Output Expected:
The output expected is divided into 2 categories:
I had previously built an object detection system using the YOLOv5 algorithm which was then trained to detect objects on few custom categories. I am now wondering how to proceed further for this pose estimation problem with the bounding boxes that I obtained using YOLOv5.
I am currently working on my master's thesis in 3D Pose Estimation, Computer Vision.
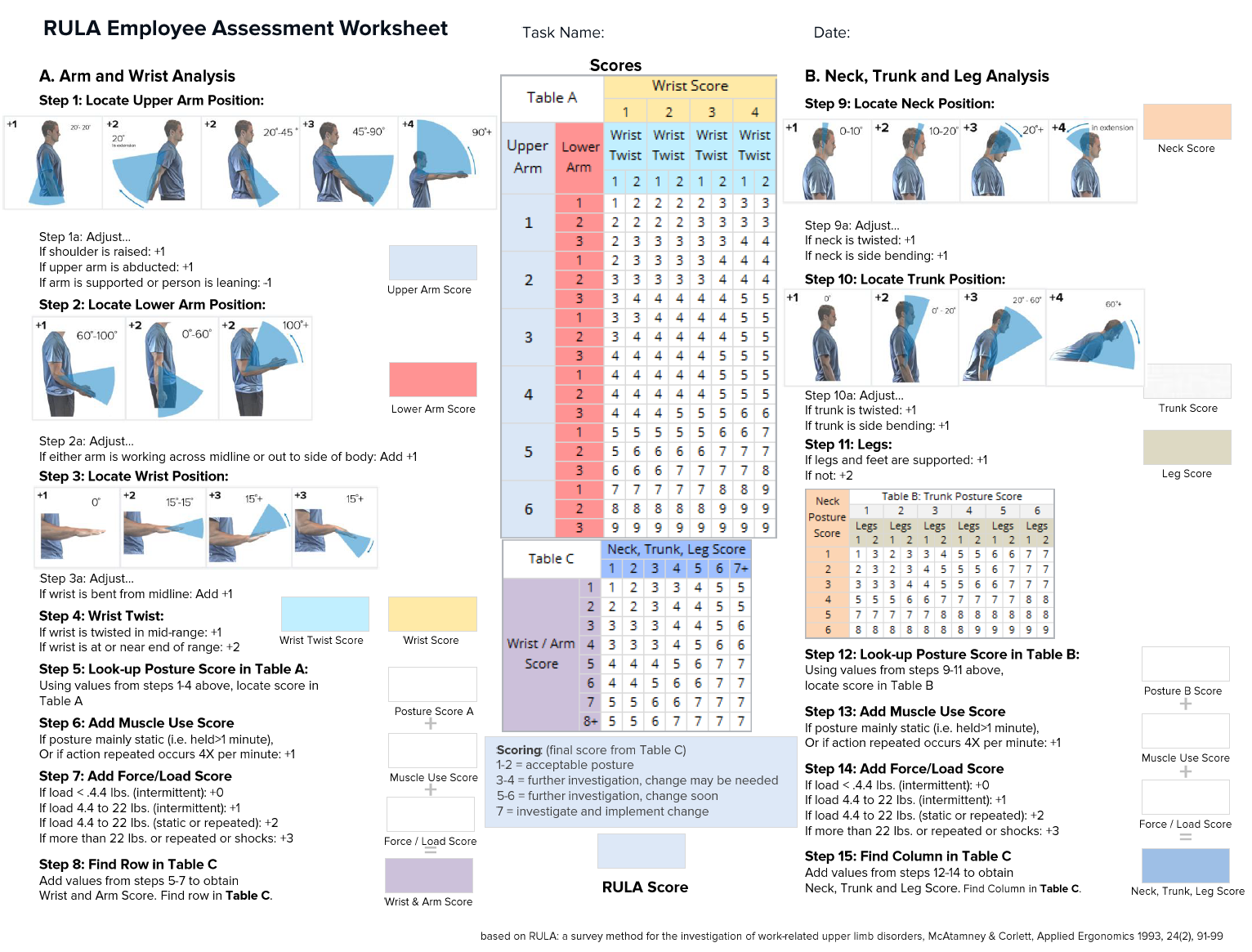
Therefore I am searching for a Rapid Upper Limb Assessment (RULA) or Rapid Entire Body Assessment (REBA) video dataset for 3D pose estimation with ground truth (either as 3D pose or depth). Perfect was RGB-D [d=depth] videos with GT as 3D pose.
Sample: RULA Employee Assessment Worksheet by ErgoPlus
In particular I am looking for a single-person video dataset. Ideally the person moves only one limb at a time, recorded like in a natural doctor's office (no need for articial scenery as well as non-essentially clean "laboratory conditions").
Feel free to even point my nose on something. Even by googleing I feel stuck now.
Thank you in advance for your time :)
I am writing my thesis in Germany where afaik RULA apps do not exist yet. I have no commercial affiliation.
We present PoseFormer, a purely transformer-based approach for 3D human pose estimation in videos without convolutional architectures involved.
We design a spatial-temporal transformer structure to comprehensively model the human joint relations within each frame as well as the temporal correlations across frames, then output an accurate 3D human pose of the center frame.
We quantitatively and qualitatively evaluate our method on two popular and standard benchmark datasets: Human3.6M and MPI-INF-3DHP.
Extensive experiments show that PoseFormer achieves state-of-the-art performance on both datasets.
Paper: https://arxiv.org/pdf/2103.10455.pdf
Code: https://github.com/zczcwh/PoseFormer
PoseFormer: 3D Human Pose Estimation with Spatial and Temporal Transformers
Hello, I'm working on a project where I need to estimate the 6DOF pose of a known 3D CAD object in a single RGB image - i.e. this task: https://paperswithcode.com/task/6d-pose-estimation. There are several constraints on the problem:
- Usable commercially (licensed under BSD, MIT, BOOST, etc.), not GPL.
- The CAD object is known and we do NOT aim for generality (i.e.recognize the class of all chairs).
- The CAD object can be uploaded by a user, so it may have symmetries and a range of textures.
- Inference step will be run on a smartphone, and should be able to run at >30fps.
- Can be anywhere on the scale of single instance of a single object to multiple instances of multiple objects (MiMo). MiMO is preferred, but not required.
- If a deep learning approach is used, the training time required for a new CAD object should be on the order of hours, not days.
- Can either 1) just find the initial pose of an object and not have any refinement steps after or 2) find the initial pose of the object and also have refinement steps after.
I am open to traditional approaches (i.e. 2D->3D correspondences then solving with PnP), but it seems like deep learning approaches outperform them (classical are too slow - https://stackoverflow.com/questions/62187435/real-time-6d-pose-estimation-of-known-3d-cad-objects-from-a-single-2d-image-or-p). Looking at deep learning approaches (poseCNN, HybridPose, Pix2Pose, CosyPose), it seems most of them match these constraints, except that they require model training time. Though perhaps I can use a single pre-trained model and then specialize it for each new CAD object with a shorter training step. So, my question: would somebody know of a commercially usable implementation that doesn't require extensive training time for a new CAD object?
A new study by Facebook AI and the University of Notre Dame research team has proposed a novel real-time six DoF (Degrees of Freedom) 3D face pose estimation technique, named Img2pose, that works without face detection or landmark localization.
6 DoF means the freedom of movement of a body in 3D space in six different ways. Other than yaw, pitch and roll rotational motion that is already there in 3 DoF, 6 DoF face pose estimation adds front/back, up/down, and left/right variables. The proposed technique can directly estimate the 6DoF 3D face pose for all faces, even in very crowded images, without the face detection step.
Summary: https://www.marktechpost.com/2020/12/23/the-university-of-notre-dame-and-facebook-ai-research-propose-img2pose-a-real-time-6dof-3d-face-pose-estimation-without-face-detection-or-landmark-localization/
Paper: https://arxiv.org/pdf/2012.07791.pdf
GitHub: https://github.com/vitoralbiero/img2pose
InterHand2.6M (ECCV 2020) is our new 3D interacting hand pose dataset.
This is the first large-scale, real-captured, and marker-less 3D interacting hand pose dataset with accurate GT 3D poses.
Checkout our InterHand2.6M
* arxiv: https://arxiv.org/abs/2008.09309
* code: https://github.com/facebookresearch/InterHand2.6M
* dataset: https://mks0601.github.io/InterHand2.6M/
* youtube: https://www.youtube.com/watch?v=h66jFalMpDQ
https://i.redd.it/5w4pqavusui51.gif
I would like to estimate the pose based on 2D-3D correspondence. I have tried pnp options within OpenCv. The pose is obtained by making using of the sift keypoints and the corresponding 3d points. However the estimated pose fluctuates and 50-70 cm off. Is there any other alternatives for the same for accurate pose estimation?
For project and code/API/expert requests: click here
https://i.redd.it/am22n2x5yhg51.gif
Most recent single-image 3D pose and shape estimation methods output pretty accurate 3D poses but inaccurate shapes, particularly for people with "non-average" body shapes. This work makes some progress towards more accurate shape estimation from a single image (although it does not work very well with baggy and loose clothing).
For project and code/API/expert requests: click here
https://reddit.com/link/hak4jd/video/hzhyncvdfe551/player
Experiments show that their approach outperforms previous methods on standard 3D pose benchmarks, while their proposed losses enable more coherent reconstruction in natural images
Hi everyone! :)
One of my former students developed a very cool point cloud labeling tool, called labelCloud! The tool provides smooth labeling interaction with 3D point clouds to support users in generating training data for #3DObjectDetection and #6DPoseEstimation.
labelCloud is publicly available, easy to install, and simple to use. Check out our github: https://github.com/ch-sa/labelCloud
If you give it a go, we would be more than happy to receive your feedback on it. So, as we are currently evaluating it, we invite you to fill this short questionaire https://forms.gle/moEyjGSa1Eiiq7VT8 (~5 min)! Thanks in advance! :)
Further information can be found in our paper from CAD'21 conference: http://dx.doi.org/10.14733/cadconfP.2021.319-323
We present PoseFormer, a purely transformer-based approach for 3D human pose estimation in videos without convolutional architectures involved.
We design a spatial-temporal transformer structure to comprehensively model the human joint relations within each frame as well as the temporal correlations across frames, then output an accurate 3D human pose of the center frame.
We quantitatively and qualitatively evaluate our method on two popular and standard benchmark datasets: Human3.6M and MPI-INF-3DHP.
Extensive experiments show that PoseFormer achieves state-of-the-art performance on both datasets.
Paper: https://arxiv.org/pdf/2103.10455.pdf
Code: https://github.com/zczcwh/PoseFormer
3D Human Pose Estimation on Videos in the Wild using PoseFormer
InterHand2.6M (ECCV 2020) is our new 3D interacting hand pose dataset.
This is the first large-scale, real-captured, and marker-less 3D interacting hand pose dataset with accurate GT 3D poses.
Checkout our InterHand2.6M
* arxiv: https://arxiv.org/abs/2008.09309
* code: https://github.com/facebookresearch/InterHand2.6M
* dataset: https://mks0601.github.io/InterHand2.6M/
* youtube: https://www.youtube.com/watch?v=h66jFalMpDQ
https://i.redd.it/snr00rm2sui51.gif
Please note that this site uses cookies to personalise content and adverts, to provide social media features, and to analyse web traffic. Click here for more information.

{kind=link}